
Parameter Estimation
The term parameter estimation refers to the process of using sample data (in reliability engineering, usually times-to-failure or success data) to estimate the parameters of the selected distribution. Several parameter estimation methods are available. This section presents an overview of the available methods used in life data analysis. More specifically, we start with the relatively simple method of Probability Plotting and continue with the more sophisticated methods of Rank Regression (or Least Squares), Maximum Likelihood Estimation and Bayesian Estimation Methods.
Probability Plotting
The least mathematically intensive method for parameter estimation is the method of probability plotting. As the term implies, probability plotting involves a physical plot of the data on specially constructed probability plotting paper. This method is easily implemented by hand, given that one can obtain the appropriate probability plotting paper.
The method of probability plotting takes the cdf of the distribution and attempts to linearize it by employing a specially constructed paper. The following sections illustrate the steps in this method using the 2-parameter Weibull distribution as an example. This includes:
- Linearize the unreliability function
- Construct the probability plotting paper
- Determine the X and Y positions of the plot points
And then using the plot to read any particular time or reliability/unreliability value of interest.
Linearizing the Unreliability Function
In the case of the 2-parameter Weibull, the cdf (also the unreliability
 ) is given by:
) is given by:



This function can then be linearized (i.e., put in the common form of
 format) as follows:
format) as follows:


![{\displaystyle {\begin{aligned}Q(t)=&1-{e^{-\left({\tfrac {t}{\eta }}\right)^{\beta }}}\\\ln(1-Q(t))=&\ln \left[{e^{-\left({\tfrac {t}{\eta }}\right)^{\beta }}}\right]\\\ln(1-Q(t))=&-\left({\tfrac {t}{\eta }}\right)^{\beta }\\\ln(-\ln(1-Q(t)))=&\beta \left(\ln \left({\frac {t}{\eta }}\right)\right)\\\ln \left(\ln \left({\frac {1}{1-Q(t)}}\right)\right)=&\beta \ln {t}-\beta \ln {\eta }\\\end{aligned}}\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/72496b83d8186326dcdbcbe8cc7265d6f69bd6bf)
Then by setting:


and:


the equation can then be rewritten as:


which is now a linear equation with a slope of:


and an intercept of:


Constructing the Paper
The next task is to construct the Weibull probability plotting paper with the appropriate y and x axes. The x-axis transformation is simply logarithmic. The y-axis is a bit more complex, requiring a double log reciprocal transformation, or:


where  is the unreliability.
is the unreliability.
Such papers have been created by different vendors and are called probability plotting papers.
To illustrate, consider the following probability plot on a slightly different type of Weibull probability paper.
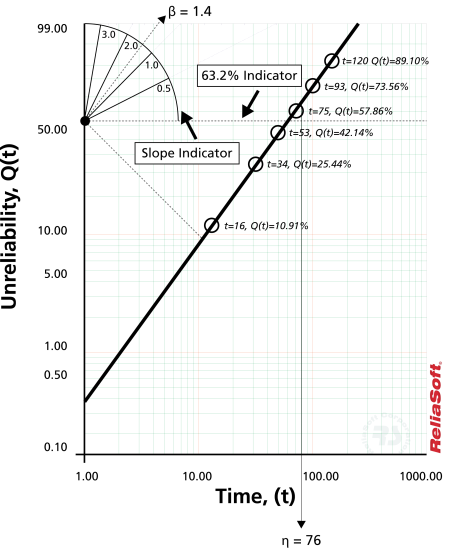
This paper is constructed based on the mentioned y and x transformations, where the y-axis represents unreliability and the x-axis represents time. Both of these values must be known for each time-to-failure point we want to plot.
Then, given the  and
and
 value for each point, the points can easily be put on the plot. Once the points have been placed on the plot, the best possible straight line is drawn through these points. Once the line has been drawn, the slope of the line can be obtained (some probability papers include a slope indicator to simplify this calculation). This is the parameter
value for each point, the points can easily be put on the plot. Once the points have been placed on the plot, the best possible straight line is drawn through these points. Once the line has been drawn, the slope of the line can be obtained (some probability papers include a slope indicator to simplify this calculation). This is the parameter
 , which is the value of the slope. To determine the scale parameter,
, which is the value of the slope. To determine the scale parameter,
 (also called the
characteristic life), one reads the time from the x-axis corresponding to
(also called the
characteristic life), one reads the time from the x-axis corresponding to
 .
.





Note that at:


Thus, if we enter the y axis at
 , the corresponding value of
, the corresponding value of
 will be equal to
will be equal to
 . Thus, using this simple methodology, the parameters of the Weibull distribution can be estimated.
. Thus, using this simple methodology, the parameters of the Weibull distribution can be estimated.

Determining the X and Y Position of the Plot Points
The points on the plot represent our data or, more specifically, our times-to-failure data. If, for example, we tested four units that failed at 10, 20, 30 and 40 hours, then we would use these times as our x values or time values.
Determining the appropriate y plotting positions, or the unreliability values, is a little more complex. To determine the y plotting positions, we must first determine a value indicating the corresponding unreliability for that failure. In other words, we need to obtain the cumulative percent failed for each time-to-failure. For example, the cumulative percent failed by 10 hours may be 25%, by 20 hours 50%, and so forth. This is a simple method illustrating the idea. The problem with this simple method is the fact that the 100% point is not defined on most probability plots; thus, an alternative and more robust approach must be used. The most widely used method of determining this value is the method of obtaining the median rank for each failure, as discussed next.
Median Ranks
The Median Ranks method is used to obtain an estimate of the unreliability for each failure. The median rank is the value that the true probability of failure,
 , should have at the
, should have at the
 failure out of a sample of
failure out of a sample of
 units at the 50% confidence level.
units at the 50% confidence level.



The rank can be found for any percentage point,
 , greater than zero and less than one, by solving the cumulative binomial equation for
, greater than zero and less than one, by solving the cumulative binomial equation for
 . This represents the rank, or unreliability estimate, for the
. This represents the rank, or unreliability estimate, for the
 failure in the following equation for the cumulative binomial:
failure in the following equation for the cumulative binomial:




where  is the sample size and
is the sample size and
 the order number.
the order number.

The median rank is obtained by solving this equation for
 at
at
 :
:



For example, if  and we have four failures, we would solve the median rank equation for the value of
and we have four failures, we would solve the median rank equation for the value of
 four times; once for each failure with
four times; once for each failure with
 . This result can then be used as the unreliability estimate for each failure or the
. This result can then be used as the unreliability estimate for each failure or the
 plotting position. (See also
The Weibull Distribution for a step-by-step example of this method.) The solution of cumulative binomial equation for
plotting position. (See also
The Weibull Distribution for a step-by-step example of this method.) The solution of cumulative binomial equation for
 requires the use of numerical methods.
requires the use of numerical methods.


Beta and F Distributions Approach
A more straightforward and easier method of estimating median ranks is by applying two transformations to the cumulative binomial equation, first to the beta distribution and then to the F distribution, resulting in [12, 13]:


where  denotes the
denotes the
 distribution at the 0.50 point, with
distribution at the 0.50 point, with
 and
and
 degrees of freedom, for failure
degrees of freedom, for failure
 out of
out of
 units.
units.




Benard's Approximation for Median Ranks
Another quick, and less accurate, approximation of the median ranks is also given by:


This approximation of the median ranks is also known as Benard's approximation.
Kaplan-Meier
The Kaplan-Meier estimator (also known as the product limit estimator) is used as an alternative to the median ranks method for calculating the estimates of the unreliability for probability plotting purposes. The equation of the estimator is given by:


where:


Probability Plotting Example
This same methodology can be applied to other distributions with
cdf equations that can be linearized. Different probability papers exist for each distribution, because different distributions have different
cdf equations. ReliaSoft's software tools automatically create these plots for you. Special scales on these plots allow you to derive the parameter estimates directly from the plots, similar to the way
 and
and
 were obtained from the Weibull probability plot. The following example demonstrates the method again, this time using the 1-parameter exponential distribution.
were obtained from the Weibull probability plot. The following example demonstrates the method again, this time using the 1-parameter exponential distribution.
Let's assume six identical units are reliability tested at the same application and operation stress levels. All of these units fail during the test after operating for the following times (in hours): 96, 257, 498, 763, 1051 and 1744.
The steps for using the probability plotting method to determine the parameters of the exponential pdf representing the data are as follows:
Rank the times-to-failure in ascending order as shown next.
| Failure Time (hr) | Failure Order Number
out of Sample Size of 6 |
|---|---|
| 96 | 1 |
| 257 | 2 |
| 498 | 3 |
| 763 | 4 |
| 1,051 | 5 |
| 1,744 | 6 |
Obtain their median rank plotting positions. Median rank positions are used instead of other ranking methods because median ranks are at a specific confidence level (50%).
The times-to-failure, with their corresponding median ranks, are shown next:
| Failure Time (hr) | Median
Rank, % |
|---|---|
| 96 | 10.91 |
| 257 | 26.44 |
| 498 | 42.14 |
| 763 | 57.86 |
| 1,051 | 73.56 |
| 1,744 | 89.10 |
On an exponential probability paper, plot the times on the x-axis and their corresponding rank value on the y-axis. The next figure displays an example of an exponential probability paper. The paper is simply a log-linear paper.
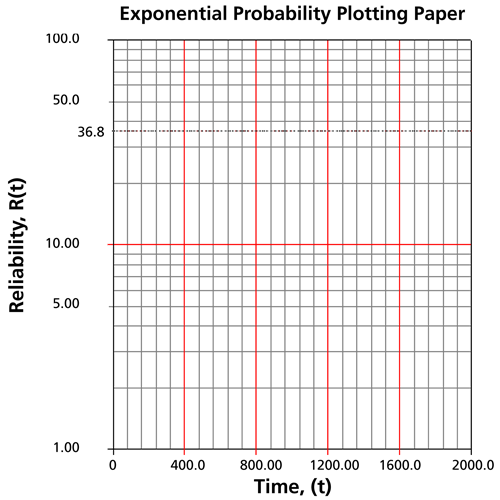
Draw the best possible straight line that goes through the
 and
and
 point and through the plotted points (as shown in the plot below).
point and through the plotted points (as shown in the plot below).


At the  or
or
 ordinate point, draw a
straight horizontal line until this line intersects the fitted straight line. Draw a vertical line through this intersection until it crosses the abscissa. The value at the intersection of the abscissa is the estimate of the mean. For this case,
ordinate point, draw a
straight horizontal line until this line intersects the fitted straight line. Draw a vertical line through this intersection until it crosses the abscissa. The value at the intersection of the abscissa is the estimate of the mean. For this case,
 hours which means that
hours which means that
 (This is always at 63.2% because
(This is always at 63.2% because
 .
.




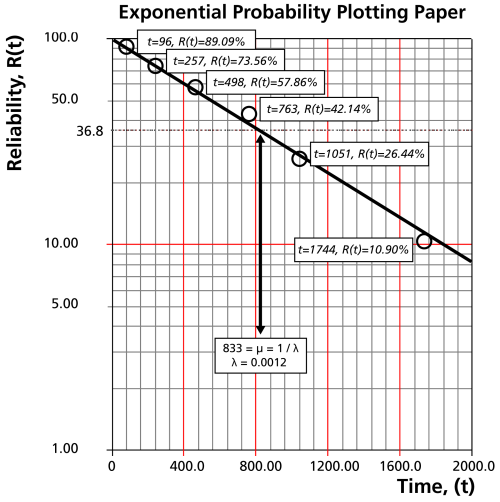
Now any reliability value for any mission time
 can be obtained. For example, the
reliability for a mission of 15 hours, or any other time, can now be obtained either from the plot or analytically.
can be obtained. For example, the
reliability for a mission of 15 hours, or any other time, can now be obtained either from the plot or analytically.
To obtain the value from the plot, draw a vertical line from the abscissa, at
 hours, to the fitted line. Draw a horizontal line from this intersection to the ordinate and read
hours, to the fitted line. Draw a horizontal line from this intersection to the ordinate and read
 . In this case,
. In this case,
 . This can also be obtained
analytically, from the exponential reliability function.
. This can also be obtained
analytically, from the exponential reliability function.



Comments on the Probability Plotting Method
Besides the most obvious drawback to probability plotting, which is the amount of effort required, manual probability plotting is not always consistent in the results. Two people plotting a straight line through a set of points will not always draw this line the same way, and thus will come up with slightly different results. This method was used primarily before the widespread use of computers that could easily perform the calculations for more complicated parameter estimation methods, such as the least squares and maximum likelihood methods.
Least Squares (Rank Regression)
Using the idea of probability plotting, regression analysis mathematically fits the best straight line to a set of points, in an attempt to estimate the parameters. Essentially, this is a mathematically based version of the probability plotting method discussed previously.
The method of linear least squares is used for all regression analysis performed by Weibull++, except for the cases of the 3-parameter Weibull, mixed Weibull, gamma and generalized gamma distributions, where a non-linear regression technique is employed. The terms
linear regression and least squares are used synonymously in this reference. In Weibull++, the term
rank regression is used instead of least squares, or linear regression, because the regression is performed on the rank values, more specifically, the median rank values (represented on the y-axis). The method of least squares requires that a straight line be fitted to a set of data points, such that the sum of the squares of the distance of the points to the fitted line is minimized. This minimization can be performed in either the vertical or horizontal direction. If the regression is on
 , then the line is fitted so that the horizontal deviations from the points to the line are minimized. If the regression is on Y, then this means that the distance of the vertical deviations from the points to the line is minimized. This is illustrated in the following figure.
, then the line is fitted so that the horizontal deviations from the points to the line are minimized. If the regression is on Y, then this means that the distance of the vertical deviations from the points to the line is minimized. This is illustrated in the following figure.

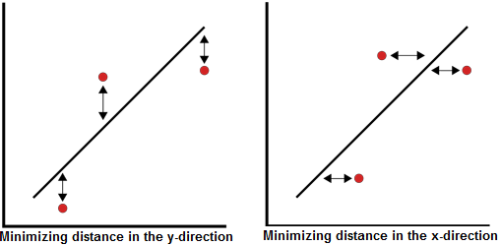
Rank Regression on Y
Assume that a set of data pairs  ,
,
 ,...,
,...,
 were obtained and plotted, and that the
were obtained and plotted, and that the
 -values are known exactly. Then, according to the
least squares principle, which minimizes the vertical distance between the data points and the straight line fitted to the data, the best fitting straight line to these data is the straight line
-values are known exactly. Then, according to the
least squares principle, which minimizes the vertical distance between the data points and the straight line fitted to the data, the best fitting straight line to these data is the straight line
 (where the recently introduced (
(where the recently introduced ( ) symbol indicates that this value is an estimate) such that:
) symbol indicates that this value is an estimate) such that:







and where  and
and
 are the
least squares estimates of
are the
least squares estimates of  and
and
 , and
, and
 is the number of data points. These equations are minimized by estimates of
is the number of data points. These equations are minimized by estimates of
 and
and
 such that:
such that:








and:


Rank Regression on X
Assume that a set of data pairs ..,
 ,...,
,...,
 were obtained and plotted, and that the y-values are known exactly. The same least squares principle is applied, but this time, minimizing the horizontal distance between the data points and the straight line fitted to the data. The best fitting straight line to these data is the straight line
were obtained and plotted, and that the y-values are known exactly. The same least squares principle is applied, but this time, minimizing the horizontal distance between the data points and the straight line fitted to the data. The best fitting straight line to these data is the straight line
 such that:
such that:



Again,  and
and
 are the least squares estimates of and
are the least squares estimates of and
 , and
, and
 is the number of data points. These equations are minimized by estimates of
is the number of data points. These equations are minimized by estimates of
 and
and
 such that:
such that:


- and:


The corresponding relations for determining the parameters for specific distributions (i.e., Weibull, exponential, etc.), are presented in the chapters covering that distribution.
Correlation Coefficient
The correlation coefficient is a measure of how well the linear regression model fits the data and is usually denoted by
 . In the case of life data analysis, it is a measure for the strength of the linear relation (correlation) between the median ranks and the data. The population correlation coefficient is defined as follows:
. In the case of life data analysis, it is a measure for the strength of the linear relation (correlation) between the median ranks and the data. The population correlation coefficient is defined as follows:



where  covariance of
covariance of
 and
and
 ,
,
 standard deviation of
standard deviation of
 , and
, and
 standard deviation of
standard deviation of
 .
.



The estimator of  is the sample correlation coefficient,
is the sample correlation coefficient,
 , given by:
, given by:



The range of  is
is
 .
.

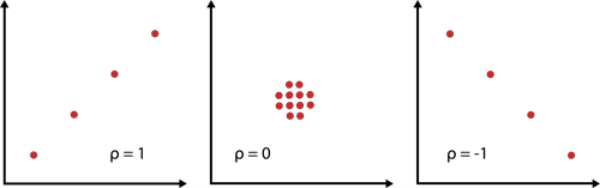
The closer the value is to  , the better the linear fit. Note that +1 indicates a perfect fit (the paired values (
, the better the linear fit. Note that +1 indicates a perfect fit (the paired values ( ) lie on a straight line) with a positive slope, while -1 indicates a perfect fit with a negative slope. A correlation coefficient value of zero would indicate that the data are randomly scattered and have no pattern or correlation in relation to the regression line model.
) lie on a straight line) with a positive slope, while -1 indicates a perfect fit with a negative slope. A correlation coefficient value of zero would indicate that the data are randomly scattered and have no pattern or correlation in relation to the regression line model.


Comments on the Least Squares Method
The least squares estimation method is quite good for functions that can be linearized. For these distributions, the calculations are relatively easy and straightforward, having closed-form solutions that can readily yield an answer without having to resort to numerical techniques or tables. Furthermore, this technique provides a good measure of the goodness-of-fit of the chosen distribution in the correlation coefficient. Least squares is generally best used with data sets containing complete data, that is, data consisting only of single times-to-failure with no censored or interval data. (See Life Data Classification for information about the different data types, including complete, left censored, right censored (or suspended) and interval data.)
See also:
Rank Methods for Censored Data
All available data should be considered in the analysis of times-to-failure data. This includes the case when a particular unit in a sample has been removed from the test prior to failure. An item, or unit, which is removed from a reliability test prior to failure, or a unit which is in the field and is still operating at the time the reliability of these units is to be determined, is called a suspended item or right censored observation or right censored data point. Suspended items analysis would also be considered when:
- We need to make an analysis of the available results before test completion.
- The failure modes which are occurring are different than those anticipated and such units are withdrawn from the test.
- We need to analyze a single mode and the actual data set comprises multiple modes.
- A warranty analysis is to be made of all units in the field (non-failed and failed units). The non-failed units are considered to be suspended items (or right censored).
This section describes the rank methods that are used in both probability plotting and least squares (rank regression) to handle censored data. This includes:
- The rank adjustment method for right censored (suspension) data.
- ReliaSoft's alternative ranking method for censored data including left censored, right censored, and interval data.
Rank Adjustment Method for Right Censored Data
When using the probability plotting or least squares (rank regression) method for data sets where some of the units did not fail, or were suspended, we need to adjust their probability of failure, or unreliability. As discussed before, estimates of the unreliability for complete data are obtained using the median ranks approach. The following methodology illustrates how adjusted median ranks are computed to account for right censored data. To better illustrate the methodology, consider the following example in Kececioglu [20] where five items are tested resulting in three failures and two suspensions.
| Item Number
(Position) | Failure (F)
or Suspension (S) | Life of item, hr |
|---|---|---|
| 1 |  | 5,100 |
| 2 |  | 9,500 |
| 3 |  | 15,000 |
| 4 |  | 22,000 |
| 5 |  | 40,000 |





The methodology for plotting suspended items involves adjusting the rank positions and plotting the data based on new positions, determined by the location of the suspensions. If we consider these five units, the following methodology would be used: The first item must be the first failure; hence, it is assigned failure order number
 . The actual failure order number (or position) of the second failure,
. The actual failure order number (or position) of the second failure,
 is in doubt. It could either be in position 2 or in position 3. Had
is in doubt. It could either be in position 2 or in position 3. Had
 not been withdrawn from the test at 9,500 hours, it could have operated successfully past 15,000 hours, thus placing
not been withdrawn from the test at 9,500 hours, it could have operated successfully past 15,000 hours, thus placing
 in position 2. Alternatively,
in position 2. Alternatively,
 could also have failed before 15,000 hours, thus placing
could also have failed before 15,000 hours, thus placing
 in position 3. In this case, the failure order number for
in position 3. In this case, the failure order number for
 will be some number between 2 and 3. To determine this number, consider the following:
will be some number between 2 and 3. To determine this number, consider the following:

We can find the number of ways the second failure can occur in either order number 2 (position 2) or order number 3 (position 3). The possible ways are listed next.
 in Position 2 in Position 2
|  in Position 3 in Position 3
| |||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 1 | 2 | |
 |  |  |  |  |  |  |  | |
 |  |  |  |  |  | OR |  |  |
 |  |  |  |  |  |  |  | |
 |  |  |  |  |  |  |  | |
 |  |  |  |  |  |  |  | |
It can be seen that  can occur in the second position six ways and in the third position two ways. The most probable position is the average of these possible ways, or the
mean order number ( MON ), given by:
can occur in the second position six ways and in the third position two ways. The most probable position is the average of these possible ways, or the
mean order number ( MON ), given by:


Using the same logic on the third failure, it can be located in position numbers 3, 4 and 5 in the possible ways listed next.
 in Position 3 in Position 3
|  in Position 4 in Position 4
|  in Position 5 in Position 5 | |||||||
| 1 | 2 | 1 | 2 | 3 | 1 | 2 | 3 | ||
 |  |  |  > >
|  |  |  |  | ||
 |  | OR |  |  |  | OR |  |  |  |
 |  |  |  |  |  |  |  | ||
 |  |  |  |  |  |  |  | ||
 |  |  |  |  |  |  |  | ||
Then, the mean order number for the third failure, (item 5) is:


Once the mean order number for each failure has been established, we obtain the median rank positions for these failures at their mean order number. Specifically, we obtain the median rank of the order numbers 1, 2.25 and 4.125 out of a sample size of 5, as given next.
| Plotting Positions for the Failures (Sample Size=5) | ||
|---|---|---|
| Failure Number | MON | Median Rank Position(%) |
1: | 1 | 13% |
2: | 2.25 | 36% |
3: | 4.125 | 71% |
Once the median rank values have been obtained, the probability plotting analysis is identical to that presented before. As you might have noticed, this methodology is rather laborious. Other techniques and shortcuts have been developed over the years to streamline this procedure. For more details on this method, see Kececioglu [20]. Here, we will introduce one of these methods. This method calculates MON using an increment, I, which is defined by:


Where:
- N= the sample size, or total number of items in the test
- PMON = previous mean order number
- NIBPSS = the number of items beyond the present suspended set. It is the number of units (including all the failures and suspensions) at the current failure time.
- i = the ith failure item
MON is given as:


Let's calculate the previous example using the method.
For F1:


For F2:


For F3:


The MON obtained for each failure item via this method is same as from the first method, so the median rank values will also be the same.
For Grouped data, the increment  at each failure group will be multiplied by the number of failures in that group.
at each failure group will be multiplied by the number of failures in that group.

Shortfalls of the Rank Adjustment Method
Even though the rank adjustment method is the most widely used method for performing analysis for analysis of suspended items, we would like to point out the following shortcoming. As you may have noticed, only the position where the failure occurred is taken into account, and not the exact time-to-suspension. For example, this methodology would yield the exact same results for the next two cases.
| Case 1 | Case 2 | ||||
|---|---|---|---|---|---|
| Item Number | State*"F" or "S" | Life of an item, hr | Item number | State*,"F" or "S" | Life of item, hr |
| 1 |  | 1,000 | 1 |  | 1,000 |
| 2 |  | 1,100 | 2 |  | 9,700 |
| 3 |  | 1,200 | 3 |  | 9,800 |
| 4 |  | 1,300 | 4 |  | 9,900 |
| 5 |  | 10,000 | 5 |  | 10,000 |
| * F - Failed, S - Suspended | * F - Failed, S - Suspended | ||||

This shortfall is significant when the number of failures is small and the number of suspensions is large and not spread uniformly between failures, as with these data. In cases like this, it is highly recommended to use maximum likelihood estimation (MLE) to estimate the parameters instead of using least squares, because MLE does not look at ranks or plotting positions, but rather considers each unique time-to-failure or suspension. For the data given above, the results are as follows. The estimated parameters using the method just described are the same for both cases (1 and 2):


However, the MLE results for Case 1 are:


And the MLE results for Case 2 are:


As we can see, there is a sizable difference in the results of the two sets calculated using MLE and the results using regression with the SRM. The results for both cases are identical when using the regression estimation technique with SRM, as SRM considers only the positions of the suspensions. The MLE results are quite different for the two cases, with the second case having a much larger value of
 , which is due to the higher values of the suspension times in Case 2. This is because the maximum likelihood technique, unlike rank regression with SRM, considers the values of the suspensions when estimating the parameters. This is illustrated in the
discussion of MLE given below.
, which is due to the higher values of the suspension times in Case 2. This is because the maximum likelihood technique, unlike rank regression with SRM, considers the values of the suspensions when estimating the parameters. This is illustrated in the
discussion of MLE given below.
One alternative to improve the regression method is to use the following ReliaSoft Ranking Method (RRM) to calculate the rank. RRM does consider the effect of the censoring time.
ReliaSoft's Ranking Method (RRM) for Interval Censored Data
When analyzing interval data, it is commonplace to assume that the actual failure time occurred at the midpoint of the interval. To be more conservative, you can use the starting point of the interval or you can use the end point of the interval to be most optimistic. Weibull++ allows you to employ ReliaSoft's ranking method (RRM) when analyzing interval data. Using an iterative process, this ranking method is an improvement over the standard ranking method (SRM).
When analyzing left or right censored data, RRM also considers the effect of the actual censoring time. Therefore, the resulted rank will be more accurate than the SRM where only the position not the exact time of censoring is used.
For more details on this method see ReliaSoft's Ranking Method.
Maximum Likelihood Estimation (MLE)
From a statistical point of view, the method of maximum likelihood estimation method is, with some exceptions, considered to be the most robust of the parameter estimation techniques discussed here. The method presented in this section is for complete data (i.e., data consisting only of times-to-failure). The analysis for right censored (suspension) data, and for interval or left censored data, are then discussed in the following sections.
The basic idea behind MLE is to obtain the most likely values of the parameters, for a given distribution, that will best describe the data. As an example, consider the following data (-3, 0, 4) and assume that you are trying to estimate the mean of the data. Now, if you have to choose the most likely value for the mean from -5, 1 and 10, which one would you choose? In this case, the most likely value is 1 (given your limit on choices). Similarly, under MLE, one determines the most likely values for the parameters of the assumed distribution. It is mathematically formulated as follows.
If  is a continuous random variable with
pdf:
is a continuous random variable with
pdf:


where  are
are
 unknown parameters which need to be estimated, with R independent observations,
unknown parameters which need to be estimated, with R independent observations, , which correspond in the case of life data analysis to failure times. The likelihood function is given by:
, which correspond in the case of life data analysis to failure times. The likelihood function is given by:







The logarithmic likelihood function is given by:


The maximum likelihood estimators (or parameter values) of
 are obtained by maximizing
are obtained by maximizing
 or
or
 .
.


By maximizing  which is much easier to work with than
which is much easier to work with than
 , the maximum likelihood estimators (MLE) of
, the maximum likelihood estimators (MLE) of
 are the simultaneous solutions of
are the simultaneous solutions of
 equations such that:
equations such that:


Even though it is common practice to plot the MLE solutions using median ranks (points are plotted according to median ranks and the line according to the MLE solutions), this is not completely representative. As can be seen from the equations above, the MLE method is independent of any kind of ranks. For this reason, the MLE solution often appears not to track the data on the probability plot. This is perfectly acceptable because the two methods are independent of each other, and in no way suggests that the solution is wrong.
MLE for Right Censored Data
When performing maximum likelihood analysis on data with suspended items, the likelihood function needs to be expanded to take into account the suspended items. The overall estimation technique does not change, but another term is added to the likelihood function to account for the suspended items. Beyond that, the method of solving for the parameter estimates remains the same. For example, consider a distribution where
 is a continuous random variable with
pdf and cdf:
is a continuous random variable with
pdf and cdf:


where  are the unknown parameters which need to be estimated from
are the unknown parameters which need to be estimated from
 observed failures at
observed failures at
 , and
, and
 observed suspensions at
observed suspensions at
 then the likelihood function is formulated as follows:
then the likelihood function is formulated as follows:





![{\displaystyle {\begin{aligned}L({{\theta }_{1}},...,{{\theta }_{k}}|{{T}_{1}},...,{{T}_{R,}}{{S}_{1}},...,{{S}_{M}})=&{\underset {i=1}{\overset {R}{\mathop {\prod } }}}\,f({{T}_{i}};{{\theta }_{1}},{{\theta }_{2}},...,{{\theta }_{k}})\\&\cdot {\underset {j=1}{\overset {M}{\mathop {\prod } }}}\,[1-F({{S}_{j}};{{\theta }_{1}},{{\theta }_{2}},...,{{\theta }_{k}})]\end{aligned}}\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/3644a68b72be3c1ed336ba56ab71b626a36395da)
The parameters are solved by maximizing this equation. In most cases, no closed-form solution exists for this maximum or for the parameters. Solutions specific to each distribution utilizing MLE are presented in Appendix D.
MLE for Interval and Left Censored Data
The inclusion of left and interval censored data in an MLE solution for parameter estimates involves adding a term to the likelihood equation to account for the data types in question. When using interval data, it is assumed that the failures occurred in an interval; i.e., in the interval from time
 to time
to time
 (or from time 0 to time
(or from time 0 to time
 if left censored), where
if left censored), where
 . In the case of interval data, and given
. In the case of interval data, and given
 interval observations, the likelihood function is modified by multiplying the likelihood function with an additional term as follows:
interval observations, the likelihood function is modified by multiplying the likelihood function with an additional term as follows:





Note that if only interval data are present, this term will represent the entire likelihood function for the MLE solution. The next section gives a formulation of the complete likelihood function for all possible censoring schemes.
The Complete Likelihood Function
We have now seen that obtaining MLE parameter estimates for different types of data involves incorporating different terms in the likelihood function to account for complete data, right censored data, and left, interval censored data. After including the terms for the different types of data, the likelihood function can now be expressed in its complete form or:

![{\displaystyle {\begin{array}{*{35}{l}}L=&{\underset {i=1}{\mathop {{\overset {R}{\mathop {\prod } }}\,} }}\,f({{T}_{i}};{{\theta }_{1}},...,{{\theta }_{k}})\cdot {\underset {j=1}{\mathop {{\overset {M}{\mathop {\prod } }}\,} }}\,[1-F({{S}_{j}};{{\theta }_{1}},...,{{\theta }_{k}})]\\&\cdot {\underset {l=1}{\mathop {{\overset {P}{\mathop {\prod } }}\,} }}\,\left\{F({{I}_{{l}_{U}}};{{\theta }_{1}},...,{{\theta }_{k}})-F({{I}_{{l}_{L}}};{{\theta }_{1}},...,{{\theta }_{k}})\right\}\\\end{array}}\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/0cc546ec568395d91d3f08dd1a83b6c882054816)
where:


and:
 is the number of units with exact failures
is the number of units with exact failures is the number of suspended units
is the number of suspended units is the number of units with left censored or interval times-to-failure
is the number of units with left censored or interval times-to-failure are the parameters of the distribution
are the parameters of the distribution is the
is the
 time to failure
time to failure is the
is the
 time of suspension
time of suspension is the ending of the time interval of the
is the ending of the time interval of the
 group
group is the beginning of the time interval of the
is the beginning of the time interval of the
 group
group







The total number of units is  . It should be noted that in this formulation, if either
. It should be noted that in this formulation, if either
 ,
,
 or
or
 is zero then the product term associated with them is assumed to be one and not zero.
is zero then the product term associated with them is assumed to be one and not zero.

Comments on the MLE Method
The MLE method has many large sample properties that make it attractive for use. It is asymptotically consistent, which means that as the sample size gets larger, the estimates converge to the right values. It is asymptotically efficient, which means that for large samples, it produces the most precise estimates. It is asymptotically unbiased, which means that for large samples, one expects to get the right value on average. The distribution of the estimates themselves is normal, if the sample is large enough, and this is the basis for the usual Fisher Matrix Confidence Bounds discussed later. These are all excellent large sample properties.
Unfortunately, the size of the sample necessary to achieve these properties can be quite large: thirty to fifty to more than a hundred exact failure times, depending on the application. With fewer points, the methods can be badly biased. It is known, for example, that MLE estimates of the shape parameter for the Weibull distribution are badly biased for small sample sizes, and the effect can be increased depending on the amount of censoring. This bias can cause major discrepancies in analysis. There are also pathological situations when the asymptotic properties of the MLE do not apply. One of these is estimating the location parameter for the three-parameter Weibull distribution when the shape parameter has a value close to 1. These problems, too, can cause major discrepancies.
However, MLE can handle suspensions and interval data better than rank regression, particularly when dealing with a heavily censored data set with few exact failure times or when the censoring times are unevenly distributed. It can also provide estimates with one or no observed failures, which rank regression cannot do. As a rule of thumb, our recommendation is to use rank regression techniques when the sample sizes are small and without heavy censoring (censoring is discussed in Life Data Classifications). When heavy or uneven censoring is present, when a high proportion of interval data is present and/or when the sample size is sufficient, MLE should be preferred.
See also:
Bayesian Parameter Estimation Methods
Up to this point, we have dealt exclusively with what is commonly referred to as classical statistics. In this section, another school of thought in statistical analysis will be introduced, namely Bayesian statistics. The premise of Bayesian statistics (within the context of life data analysis) is to incorporate prior knowledge, along with a given set of current observations, in order to make statistical inferences. The prior information could come from operational or observational data, from previous comparable experiments or from engineering knowledge. This type of analysis can be particularly useful when there is limited test data for a given design or failure mode but there is a strong prior understanding of the failure rate behavior for that design or mode. By incorporating prior information about the parameter(s), a posterior distribution for the parameter(s) can be obtained and inferences on the model parameters and their functions can be made. This section is intended to give a quick and elementary overview of Bayesian methods, focused primarily on the material necessary for understanding the Bayesian analysis methods available in Weibull++. Extensive coverage of the subject can be found in numerous books dealing with Bayesian statistics.
Bayes's Rule
Bayes's rule provides the framework for combining prior information with sample data. In this reference, we apply Bayes's rule for combining prior information on the assumed distribution's parameter(s) with sample data in order to make inferences based on the model. The prior knowledge about the parameter(s) is expressed in terms of a
 called the
prior distribution. The posterior distribution of
called the
prior distribution. The posterior distribution of
 given the sample data, using Bayes's rule, provides the updated information about the parameters
given the sample data, using Bayes's rule, provides the updated information about the parameters
 . This is expressed with the following posterior
pdf:
. This is expressed with the following posterior
pdf:




where:
 is a vector of the parameters of the chosen distribution
is a vector of the parameters of the chosen distribution is the range of
is the range of

 is the likelihood function based on the chosen distribution and data
is the likelihood function based on the chosen distribution and data is the prior distribution for each of the parameters
is the prior distribution for each of the parameters



The integral in the Bayes's rule equation is often referred to as the marginal probability, which is a constant number that can be interpreted as the probability of obtaining the sample data given a prior distribution. Generally, the integral in the Bayes's rule equation does not have a closed form solution and numerical methods are needed for its solution.
As can be seen from the Bayes's rule equation, there is a significant difference between classical and Bayesian statistics. First, the idea of prior information does not exist in classical statistics. All inferences in classical statistics are based on the sample data. On the other hand, in the Bayesian framework, prior information constitutes the basis of the theory. Another difference is in the overall approach of making inferences and their interpretation. For example, in Bayesian analysis, the parameters of the distribution to be fitted are the random variables. In reality, there is no distribution fitted to the data in the Bayesian case.
For instance, consider the case where data is obtained from a reliability test. Based on prior experience on a similar product, the analyst believes that the shape parameter of the Weibull distribution has a value between
 and
and
 and wants to utilize this information. This can be achieved by using the Bayes theorem. At this point, the analyst is automatically forcing the Weibull distribution as a model for the data and with a shape parameter between
and wants to utilize this information. This can be achieved by using the Bayes theorem. At this point, the analyst is automatically forcing the Weibull distribution as a model for the data and with a shape parameter between
 and
and
 . In this example, the range of values for the shape parameter is the prior distribution, which in this case is Uniform. By applying Bayes's rule, the posterior distribution of the shape parameter will be obtained. Thus, we end up with a distribution for the parameter rather than an estimate of the parameter, as in classical statistics.
. In this example, the range of values for the shape parameter is the prior distribution, which in this case is Uniform. By applying Bayes's rule, the posterior distribution of the shape parameter will be obtained. Thus, we end up with a distribution for the parameter rather than an estimate of the parameter, as in classical statistics.



To better illustrate the example, assume that a set of failure data was provided along with a distribution for the shape parameter (i.e., uniform prior) of the Weibull (automatically assuming that the data are Weibull distributed). Based on that, a new distribution (the posterior) for that parameter is then obtained using Bayes's rule. This posterior distribution of the parameter may or may not resemble in form the assumed prior distribution. In other words, in this example the prior distribution of
 was assumed to be uniform but the posterior is most likely not a uniform distribution.
was assumed to be uniform but the posterior is most likely not a uniform distribution.
The question now becomes: what is the value of the shape parameter? What about the reliability and other results of interest? In order to answer these questions, we have to remember that in the Bayesian framework all of these metrics are random variables. Therefore, in order to obtain an estimate, a probability needs to be specified or we can use the expected value of the posterior distribution.
In order to demonstrate the procedure of obtaining results from the posterior distribution, we will rewrite the Bayes's rule equation for a single parameter
 :
:



The expected value (or mean value) of the parameter
 can be obtained using the equation for the mean and the Bayes's rule equation for single parameter:
can be obtained using the equation for the mean and the Bayes's rule equation for single parameter:



An alternative result for  would be the median value. Using the equation for the median and the Bayes's rule equation for a single parameter:
would be the median value. Using the equation for the median and the Bayes's rule equation for a single parameter:


The equation for the median is solved for
 the median value of
the median value of


Similarly, any other percentile of the posterior pdf can be calculated and reported. For example, one could calculate the 90th percentile of
 's posterior
pdf:
's posterior
pdf:


This calculation will be used in Confidence Bounds and The Weibull Distribution for obtaining confidence bounds on the parameter(s).
The next step will be to make inferences on the reliability. Since the parameter
 is a random variable described by the posterior
pdf, all subsequent functions of
is a random variable described by the posterior
pdf, all subsequent functions of
 are distributed random variables as well and are entirely based on the posterior
pdf of
are distributed random variables as well and are entirely based on the posterior
pdf of  . Therefore, expected value, median or other percentile values will also need to be calculated. For example, the expected reliability at time
. Therefore, expected value, median or other percentile values will also need to be calculated. For example, the expected reliability at time
 is:
is:


![{\displaystyle E[R(T|Data)]=\int _{\varsigma }^{}R(T)f(\theta |Data)d{\theta }\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/931bea0e282af5f95ee88c03c59f6cf98b576161)
In other words, at a given time  , there is a distribution that governs the reliability value at that time,
, there is a distribution that governs the reliability value at that time,
 , and by using Bayes's rule, the expected (or mean) value of the reliability is obtained. Other percentiles of this distribution can also be obtained.
A similar procedure is followed for other functions of
, and by using Bayes's rule, the expected (or mean) value of the reliability is obtained. Other percentiles of this distribution can also be obtained.
A similar procedure is followed for other functions of
 , such as failure rate, reliable life, etc.
, such as failure rate, reliable life, etc.
Prior Distributions
Prior distributions play a very important role in Bayesian Statistics. They are essentially the basis in Bayesian analysis. Different types of prior distributions exist, namely informative and non-informative. Non-informative prior distributions (a.k.a. vague, flat and diffuse) are distributions that have no population basis and play a minimal role in the posterior distribution. The idea behind the use of non-informative prior distributions is to make inferences that are not greatly affected by external information or when external information is not available. The uniform distribution is frequently used as a non-informative prior.
On the other hand, informative priors have a stronger influence on the posterior distribution. The influence of the prior distribution on the posterior is related to the sample size of the data and the form of the prior. Generally speaking, large sample sizes are required to modify strong priors, where weak priors are overwhelmed by even relatively small sample sizes. Informative priors are typically obtained from past data.