The Weibull Distribution
The Weibull distribution is one of the most widely used lifetime distributions in reliability engineering. It is a versatile distribution that can take on the characteristics of other types of distributions, based on the value of the shape parameter,
 . This chapter provides a brief background on the Weibull distribution, presents and derives most of the applicable equations and presents examples calculated both manually and by using ReliaSoft's
Weibull++ software.
. This chapter provides a brief background on the Weibull distribution, presents and derives most of the applicable equations and presents examples calculated both manually and by using ReliaSoft's
Weibull++ software.

Weibull Probability Density Function
The 3-Parameter Weibull
The 3-parameter Weibull pdf is given by:


where:








and:
-
 scale parameter, or characteristic life
scale parameter, or characteristic life shape parameter (or slope)
shape parameter (or slope) location parameter (or failure free life)
location parameter (or failure free life)



The 2-Parameter Weibull
The 2-parameter Weibull pdf is obtained by setting
 , and is given by:
, and is given by:



The 1-Parameter Weibull
The 1-parameter Weibull pdf is obtained by again setting
 and assuming
and assuming
 assumed value or:
assumed value or:



where the only unknown parameter is the scale parameter,
 .
.

Note that in the formulation of the 1-parameter Weibull, we assume that the shape parameter
 is known
a priori from past experience with identical or similar products. The advantage of doing this is that data sets with few or no failures can be analyzed.
is known
a priori from past experience with identical or similar products. The advantage of doing this is that data sets with few or no failures can be analyzed.

Weibull Distribution Functions
The Mean or MTTF
The mean,  , (also called
MTTF) of the Weibull pdf is given by:
, (also called
MTTF) of the Weibull pdf is given by:



where


is the gamma function evaluated at the value of:


The gamma function is defined as:


For the 2-parameter case, this can be reduced to:


Note that some practitioners erroneously assume that
 is equal to the MTTF,
is equal to the MTTF,
 .
This is only true for the case of:
.
This is only true for the case of:
 or:
or:



The Median
The median,  , of the Weibull distribution is given by:
, of the Weibull distribution is given by:



The Mode
The mode,  , is given by:
, is given by:



The Standard Deviation
The standard deviation,  , is given by:
, is given by:



The Weibull Reliability Function
The equation for the 3-parameter Weibull cumulative density function, cdf, is given by:


This is also referred to as unreliability and designated as
 by some authors.
by some authors.

Recalling that the reliability function of a distribution is simply one minus the cdf, the reliability function for the 3-parameter Weibull distribution is then given by:


The Weibull Conditional Reliability Function
The 3-parameter Weibull conditional reliability function is given by:


or:

![{\displaystyle R(t|T)=e^{-\left[\left({\frac {T+t-\gamma }{\eta }}\right)^{\beta }-\left({\frac {T-\gamma }{\eta }}\right)^{\beta }\right]}\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/b1d348b164c30e506563ff86ee7b4e1d91902e97)
These give the reliability for a new mission of
 duration, having already accumulated
duration, having already accumulated
 time of operation up to the start of this new mission, and the units are checked out to assure that they will start the next mission successfully. It is called conditional because you can calculate the reliability of a new mission based on the fact that the unit or units already accumulated hours of operation successfully.
time of operation up to the start of this new mission, and the units are checked out to assure that they will start the next mission successfully. It is called conditional because you can calculate the reliability of a new mission based on the fact that the unit or units already accumulated hours of operation successfully.


The Weibull Reliable Life
The reliable life,  , of a unit for a specified reliability,
, of a unit for a specified reliability,
 , starting the mission at age zero, is given by:
, starting the mission at age zero, is given by:




This is the life for which the unit/item will be functioning successfully with a reliability of
 . If
. If
 , then
, then
 , the median life, or the life by which half of the units will survive.
, the median life, or the life by which half of the units will survive.


The Weibull Failure Rate Function
The Weibull failure rate function,  , is given by:
, is given by:



Characteristics of the Weibull Distribution
The Weibull distribution is widely used in reliability and life data analysis due to its versatility. Depending on the values of the parameters, the Weibull distribution can be used to model a variety of life behaviors. We will now examine how the values of the shape parameter,
 , and the scale parameter,
, and the scale parameter,
 , affect such distribution characteristics as the shape of the curve, the reliability and the failure rate. Note that in the rest of this section we will assume the most general form of the Weibull distribution, (i.e., the 3-parameter form). The appropriate substitutions to obtain the other forms, such as the 2-parameter form where
, affect such distribution characteristics as the shape of the curve, the reliability and the failure rate. Note that in the rest of this section we will assume the most general form of the Weibull distribution, (i.e., the 3-parameter form). The appropriate substitutions to obtain the other forms, such as the 2-parameter form where
 or the 1-parameter form where
or the 1-parameter form where
 constant, can easily be made.
constant, can easily be made.


Effects of the Shape Parameter, beta
The Weibull shape parameter,  , is also known as the
slope. This is because the value of
, is also known as the
slope. This is because the value of
 is equal to the slope of the regressed line in a probability plot. Different values of the shape parameter can have marked effects on the behavior of the distribution. In fact, some values of the shape parameter will cause the distribution equations to reduce to those of other distributions. For example, when
is equal to the slope of the regressed line in a probability plot. Different values of the shape parameter can have marked effects on the behavior of the distribution. In fact, some values of the shape parameter will cause the distribution equations to reduce to those of other distributions. For example, when
 , the
pdf of the 3-parameter Weibull distribution reduces to that of the 2-parameter exponential distribution or:
, the
pdf of the 3-parameter Weibull distribution reduces to that of the 2-parameter exponential distribution or:


where  failure rate. The parameter
failure rate. The parameter
 is a pure number, (i.e., it is dimensionless).
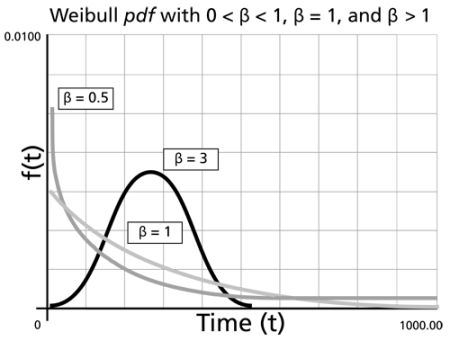
The following figure shows the effect of different values of the shape parameter,
is a pure number, (i.e., it is dimensionless).
The following figure shows the effect of different values of the shape parameter,
 , on the shape of the
pdf. As you can see, the shape can take on a variety of forms based on the value of
, on the shape of the
pdf. As you can see, the shape can take on a variety of forms based on the value of
 .
.

For  :
:

-
- As
 (or
(or
 ),
),

- As
 ,
,
 .
.  decreases monotonically and is convex as it increases beyond the value of
decreases monotonically and is convex as it increases beyond the value of
 .
.- The mode is non-existent.
- As






For  :
:

-
 at
at
 (or
(or
 ).
). increases as
increases as
 (the mode) and decreases thereafter.
(the mode) and decreases thereafter.- For
 the Weibull
pdf is positively skewed (has a right tail), for
the Weibull
pdf is positively skewed (has a right tail), for
 its coefficient of skewness approaches zero (no tail). Consequently, it may approximate the normal
pdf, and for
its coefficient of skewness approaches zero (no tail). Consequently, it may approximate the normal
pdf, and for  it is negatively skewed (left tail). The way the value of
it is negatively skewed (left tail). The way the value of
 relates to the physical behavior of the items being modeled becomes more apparent when we observe how its different values affect the reliability and failure rate functions. Note that for
relates to the physical behavior of the items being modeled becomes more apparent when we observe how its different values affect the reliability and failure rate functions. Note that for
 ,
,
 , but for
, but for
 ,
,
 This abrupt shift is what complicates MLE estimation when
This abrupt shift is what complicates MLE estimation when
 is close to 1.
is close to 1.










The Effect of beta on the cdf and Reliability Function
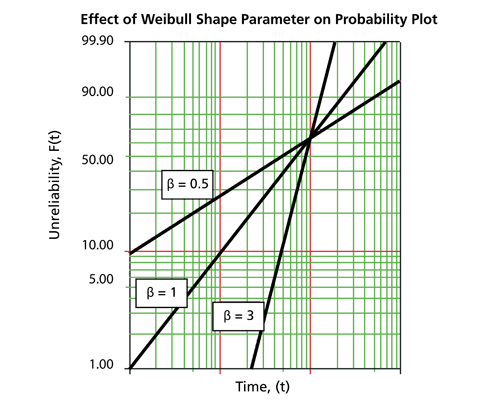
The above figure shows the effect of the value of
 on the
cdf, as manifested in the Weibull probability plot. It is easy to see why this parameter is sometimes referred to as the slope. Note that the models represented by the three lines all have the same value of
on the
cdf, as manifested in the Weibull probability plot. It is easy to see why this parameter is sometimes referred to as the slope. Note that the models represented by the three lines all have the same value of
 . The following figure shows the effects of these varied values of
. The following figure shows the effects of these varied values of
 on the reliability plot, which is a linear analog of the probability plot.
on the reliability plot, which is a linear analog of the probability plot.
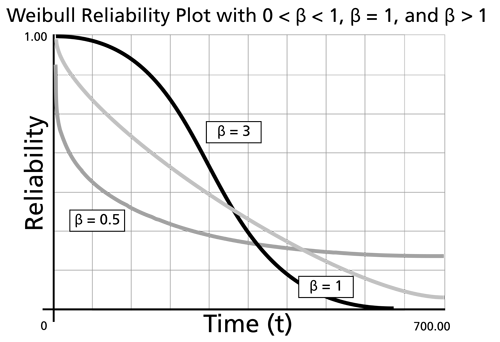
-
 decreases sharply and monotonically for
decreases sharply and monotonically for
 and is convex.
and is convex.- For
 ,
,
 decreases monotonically but less sharply than for
decreases monotonically but less sharply than for
 and is convex.
and is convex. - For
 ,
,
 decreases as increases. As wear-out sets in, the curve goes through an inflection point and decreases sharply.
decreases as increases. As wear-out sets in, the curve goes through an inflection point and decreases sharply.


The Effect of beta on the Weibull Failure Rate
The value of  has a marked effect on the failure rate of the Weibull distribution and inferences can be drawn about a population's failure characteristics just by considering whether the value of
has a marked effect on the failure rate of the Weibull distribution and inferences can be drawn about a population's failure characteristics just by considering whether the value of
 is less than, equal to, or greater than one.
is less than, equal to, or greater than one.
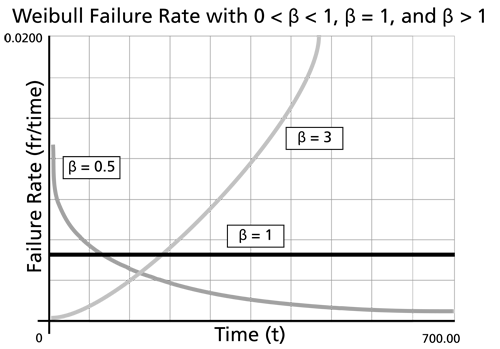
As indicated by above figure, populations with
 exhibit a failure rate that decreases with time, populations with
exhibit a failure rate that decreases with time, populations with
 have a constant failure rate (consistent with the exponential distribution) and populations with
have a constant failure rate (consistent with the exponential distribution) and populations with
 have a failure rate that increases with time. All three life stages of the bathtub curve can be modeled with the Weibull distribution and varying values of
have a failure rate that increases with time. All three life stages of the bathtub curve can be modeled with the Weibull distribution and varying values of
 . The Weibull failure rate for
. The Weibull failure rate for
 is unbounded at
is unbounded at
 (or
(or
 . The failure rate,
. The failure rate,
 decreases thereafter monotonically and is convex, approaching the value of zero as
decreases thereafter monotonically and is convex, approaching the value of zero as
 or
or
 . This behavior makes it suitable for representing the failure rate of units exhibiting early-type failures, for which the failure rate decreases with age. When encountering such behavior in a manufactured product, it may be indicative of problems in the production process, inadequate burn-in, substandard parts and components, or problems with packaging and shipping. For
. This behavior makes it suitable for representing the failure rate of units exhibiting early-type failures, for which the failure rate decreases with age. When encountering such behavior in a manufactured product, it may be indicative of problems in the production process, inadequate burn-in, substandard parts and components, or problems with packaging and shipping. For
 ,
,
 yields a constant value of
yields a constant value of
 or:
or:








This makes it suitable for representing the failure rate of chance-type failures and the useful life period failure rate of units.
For  ,
,
 increases as
increases as
 increases and becomes suitable for representing the failure rate of units exhibiting wear-out type failures. For
increases and becomes suitable for representing the failure rate of units exhibiting wear-out type failures. For
 the
the
 curve is concave, consequently the failure rate increases at a decreasing rate as
curve is concave, consequently the failure rate increases at a decreasing rate as
 increases.
increases.

For  there emerges a straight line relationship between
there emerges a straight line relationship between
 and
and
 , starting at a value of
, starting at a value of
 at
at
 , and increasing thereafter with a slope of
, and increasing thereafter with a slope of
 . Consequently, the failure rate increases at a constant rate as
. Consequently, the failure rate increases at a constant rate as
 increases. Furthermore, if
increases. Furthermore, if
 the slope becomes equal to 2, and when
the slope becomes equal to 2, and when
 ,
,
 becomes a straight line which passes through the origin with a slope of 2. Note that at
becomes a straight line which passes through the origin with a slope of 2. Note that at
 , the Weibull distribution equations reduce to that of the Rayleigh distribution.
, the Weibull distribution equations reduce to that of the Rayleigh distribution.





When  the
the
 curve is convex, with its slope increasing as
curve is convex, with its slope increasing as
 increases. Consequently, the failure rate increases at an increasing rate as
increases. Consequently, the failure rate increases at an increasing rate as
 increases, indicating wearout life.
increases, indicating wearout life.

Effects of the Scale Parameter, eta
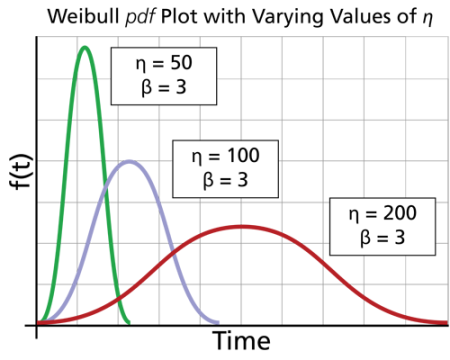
A change in the scale parameter  has the same effect on the distribution as a change of the abscissa scale. Increasing the value of
has the same effect on the distribution as a change of the abscissa scale. Increasing the value of
 while holding
while holding
 constant has the effect of stretching out the
pdf. Since the area under a pdf curve is a constant value of one, the "peak" of the
pdf curve will also decrease with the increase of
constant has the effect of stretching out the
pdf. Since the area under a pdf curve is a constant value of one, the "peak" of the
pdf curve will also decrease with the increase of
 , as indicated in the above figure.
, as indicated in the above figure.
-
- If
 is increased while
is increased while
 and
and
 are kept the same, the distribution gets stretched out to the right and its height decreases, while maintaining its shape and location.
are kept the same, the distribution gets stretched out to the right and its height decreases, while maintaining its shape and location. - If
 is decreased while
is decreased while
 and
and
 are kept the same, the distribution gets pushed in towards the left (i.e., towards its beginning or towards 0 or
are kept the same, the distribution gets pushed in towards the left (i.e., towards its beginning or towards 0 or
 ), and its height increases.
), and its height increases.  has the same units as
has the same units as
 , such as hours, miles, cycles, actuations, etc.
, such as hours, miles, cycles, actuations, etc.
- If
Effects of the Location Parameter, gamma
The location parameter,  , as the name implies, locates the distribution along the abscissa. Changing the value of
, as the name implies, locates the distribution along the abscissa. Changing the value of
 has the effect of
sliding the distribution and its associated function either to the right (if
has the effect of
sliding the distribution and its associated function either to the right (if
 ) or to the left (if
) or to the left (if
 ).
).


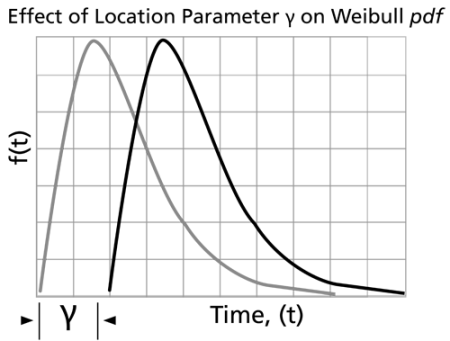
-
- When
 the distribution starts at
the distribution starts at
 or at the origin.
or at the origin. - If
 the distribution starts at the location
the distribution starts at the location
 to the right of the origin.
to the right of the origin. - If
 the distribution starts at the location
the distribution starts at the location
 to the left of the origin.
to the left of the origin.  provides an estimate of the earliest time-to-failure of such units.
provides an estimate of the earliest time-to-failure of such units.- The life period 0 to
 is a failure free operating period of such units.
is a failure free operating period of such units. - The parameter
 may assume all values and provides an estimate of the earliest time a failure may be observed. A negative
may assume all values and provides an estimate of the earliest time a failure may be observed. A negative
 may indicate that failures have occurred prior to the beginning of the test, namely during production, in storage, in transit, during checkout prior to the start of a mission, or prior to actual use.
may indicate that failures have occurred prior to the beginning of the test, namely during production, in storage, in transit, during checkout prior to the start of a mission, or prior to actual use.  has the same units as
has the same units as
 , such as hours, miles, cycles, actuations, etc.
, such as hours, miles, cycles, actuations, etc.
- When



Estimation of the Weibull Parameters
The estimates of the parameters of the Weibull distribution can be found graphically via probability plotting paper, or analytically, using either least squares (rank regression) or maximum likelihood estimation (MLE).
Probability Plotting
One method of calculating the parameters of the Weibull distribution is by using probability plotting. To better illustrate this procedure, consider the following example from Kececioglu [20].
Assume that six identical units are being reliability tested at the same application and operation stress levels. All of these units fail during the test after operating the following number of hours: 93, 34, 16, 120, 53 and 75. Estimate the values of the parameters for a 2-parameter Weibull distribution and determine the reliability of the units at a time of 15 hours.
Solution
The steps for determining the parameters of the Weibull representing the data, using probability plotting, are outlined in the following instructions. First, rank the times-to-failure in ascending order as shown next.
| Time-to-failure,
hours |
Failure Order Number
out of Sample Size of 6 |
|---|---|
| 16 | 1 |
| 34 | 2 |
| 53 | 3 |
| 75 | 4 |
| 93 | 5 |
| 120 | 6 |
Obtain their median rank plotting positions. Median rank positions are used instead of other ranking methods because median ranks are at a specific confidence level (50%). Median ranks can be found tabulated in many reliability books. They can also be estimated using the following equation:


where  is the failure order number and
is the failure order number and
 is the total sample size. The exact median ranks are found in Weibull++ by solving:
is the total sample size. The exact median ranks are found in Weibull++ by solving:




for  , where
, where
 is the sample size and
is the sample size and
 the order number. The times-to-failure, with their corresponding median ranks, are shown next.
the order number. The times-to-failure, with their corresponding median ranks, are shown next.

| Time-to-failure, hours | Median Rank,% |
|---|---|
| 16 | 10.91 |
| 34 | 26.44 |
| 53 | 42.14 |
| 75 | 57.86 |
| 93 | 73.56 |
| 120 | 89.1 |
On a Weibull probability paper, plot the times and their corresponding ranks. A sample of a Weibull probability paper is given in the following figure.
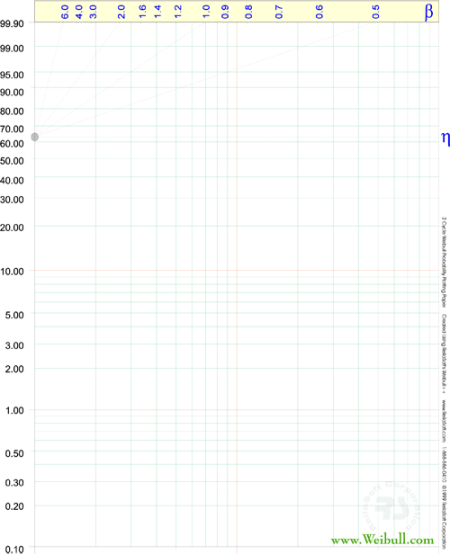
The points of the data in the example are shown in the figure below. Draw the best possible straight line through these points, as shown below, then obtain the slope of this line by drawing a line, parallel to the one just obtained, through the slope indicator. This value is the estimate of the shape parameter
 , in this case
, in this case
 .
.


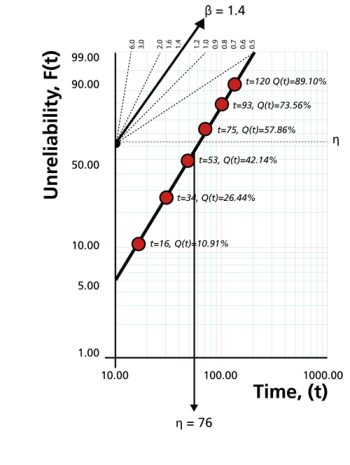
At the  ordinate point, draw a straight horizontal line until this line intersects the fitted straight line. Draw a vertical line through this intersection until it crosses the abscissa. The value at the intersection of the abscissa is the estimate of
ordinate point, draw a straight horizontal line until this line intersects the fitted straight line. Draw a vertical line through this intersection until it crosses the abscissa. The value at the intersection of the abscissa is the estimate of
 . For this case,
. For this case,
 hours. This is always at 63.2% since:
hours. This is always at 63.2% since:





Now any reliability value for any mission time
 can be obtained. For example, the reliability for a mission of 15 hours, or any other time, can now be obtained either from the plot or analytically. To obtain the value from the plot, draw a vertical line from the abscissa, at hours, to the fitted line. Draw a horizontal line from this intersection to the ordinate and read
can be obtained. For example, the reliability for a mission of 15 hours, or any other time, can now be obtained either from the plot or analytically. To obtain the value from the plot, draw a vertical line from the abscissa, at hours, to the fitted line. Draw a horizontal line from this intersection to the ordinate and read
 , in this case
, in this case
 . Thus,
. Thus,
 . This can also be obtained analytically from the Weibull reliability function since the estimates of both of the parameters are known or:
. This can also be obtained analytically from the Weibull reliability function since the estimates of both of the parameters are known or:




Probability Plotting for the Location Parameter, Gamma
The third parameter of the Weibull distribution is utilized when the data do not fall on a straight line, but fall on either a concave up or down curve. The following statements can be made regarding the value of
 :
:
- Case 1: If the curve for MR versus
 is concave down and the curve for MR versus
is concave down and the curve for MR versus
 is concave up, then there exists a
is concave up, then there exists a
 such that
such that
 , or
, or
 has a positive value.
has a positive value.



- Case 2: If the curves for MR versus
 and MR versus
and MR versus
 are both concave up, then there exists a negative
are both concave up, then there exists a negative
 which will straighten out the curve of MR versus
which will straighten out the curve of MR versus
 .
.
- Case 3: If neither one of the previous two cases prevails, then either reject the Weibull as one capable of representing the data, or proceed with the multiple population (mixed Weibull) analysis. To obtain the location parameter,
 :
:
-
-
- Subtract the same arbitrary value,
 , from all the times to failure and replot the data.
, from all the times to failure and replot the data. - If the initial curve is concave up, subtract a negative
 from each failure time.
from each failure time. - If the initial curve is concave down, subtract a positive
 from each failure time.
from each failure time. - Repeat until the data plots on an acceptable straight line.
- The value of
 is the subtracted (positive or negative) value that places the points in an acceptable straight line.
is the subtracted (positive or negative) value that places the points in an acceptable straight line.
- Subtract the same arbitrary value,
-
The other two parameters are then obtained using the techniques previously described. Also, it is important to note that we used the term subtract a positive or negative gamma, where subtracting a negative gamma is equivalent to adding it. Note that when adjusting for gamma, the x-axis scale for the straight line becomes
 .
.

Rank Regression on Y
Performing rank regression on Y requires that a straight line mathematically be fitted to a set of data points such that the sum of the squares of the vertical deviations from the points to the line is minimized. This is in essence the same methodology as the probability plotting method, except that we use the principle of least squares to determine the line through the points, as opposed to just eyeballing it. The first step is to bring our function into a linear form. For the two-parameter Weibull distribution, the (cumulative density function) is:


Taking the natural logarithm of both sides of the equation yields:

![{\displaystyle \ln[1-F(t)]=-({\frac {t}{\eta }})^{\beta }\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/9b9ee6fceedf4071fd6c00c94e8016473ee46bd6)

![{\displaystyle \ln {-\ln[1-F(t)]}=\beta \ln({\frac {t}{\eta }})\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/522429faf529a703febb4baa6246185ca1b22144)
or:

![{\displaystyle {\begin{aligned}\ln\{-\ln[1-F(t)]\}=-\beta \ln(\eta )+\beta \ln(t)\end{aligned}}\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/06bb1b1ca780fb03a632b481749bd8d1f000c8db)
Now let:

![{\displaystyle {\begin{aligned}y=\ln\{-\ln[1-F(t)]\}\end{aligned}}\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/f2cc7a0caf7f2f07bf9ef6546ff854fe89a56c0d)


and:


which results in the linear equation of:


The least squares parameter estimation method (also known as regression analysis) was discussed in Parameter Estimation, and the following equations for regression on Y were derived:


and:


In this case the equations for  and
and
 are:
are:



![{\displaystyle y_{i}=\ln \left\{-\ln[1-F(t_{i})]\right\}\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/04a931fe5c08f45d51259a807540c0beb45356c5)
and:


The  values are estimated from the median ranks.
values are estimated from the median ranks.

Once  and
and
 are obtained, then
are obtained, then
 and
and
 can easily be obtained from previous equations.
can easily be obtained from previous equations.


The Correlation Coefficient
The correlation coefficient is defined as follows:


where  = covariance of
= covariance of
 and
and
 ,
,
 = standard deviation of
= standard deviation of
 , and
, and
 = standard deviation of
= standard deviation of
 . The estimator of
. The estimator of
 is the sample correlation coefficient,
is the sample correlation coefficient,
 , given by:
, given by:









RRY Example
Consider the same data set from the probability plotting example given above (with six failures at 16, 34, 53, 75, 93 and 120 hours). Estimate the parameters and the correlation coefficient using rank regression on Y, assuming that the data follow the 2-parameter Weibull distribution.
Solution
Construct a table as shown next.
| Least Squares Analysis | |||||||
|---|---|---|---|---|---|---|---|

|

|

|

|

|

|

|

|
| 1 | 16 | 2.7726 | 0.1091 | -2.1583 | 7.6873 | 4.6582 | -5.9840 |
| 2 | 34 | 3.5264 | 0.2645 | -1.1802 | 12.4352 | 1.393 | -4.1620 |
| 3 | 53 | 3.9703 | 0.4214 | -0.6030 | 15.7632 | 0.3637 | -2.3943 |
| 4 | 75 | 4.3175 | 0.5786 | -0.146 | 18.6407 | 0.0213 | -0.6303 |
| 5 | 93 | 4.5326 | 0.7355 | 0.2851 | 20.5445 | 0.0813 | 1.2923 |
| 6 | 120 | 4.7875 | 0.8909 | 0.7955 | 22.9201 | 0.6328 | 3.8083 |

|
23.9068 | -3.007 | 97.9909 | 7.1502 | -8.0699 | ||








Utilizing the values from the table, calculate
 and
and
 using the following equations:
using the following equations:




or:


and:


or:


Therefore:


and:


or:


The correlation coefficient can be estimated as:


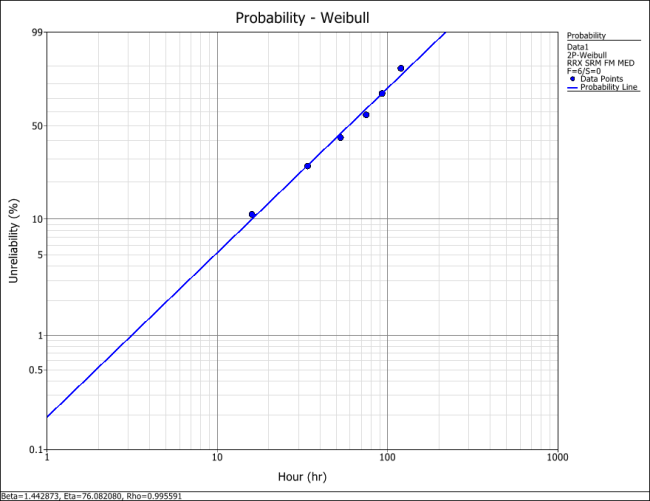
This example can be repeated in the Weibull++ software. The following plot shows the Weibull probability plot for the data set (with 90% two-sided confidence bounds).

If desired, the Weibull pdf representing the data set can be written as:

or:


You can also plot this result in Weibull++, as shown next. From this point on, different results, reports and plots can be obtained.

Rank Regression on X
Performing a rank regression on X is similar to the process for rank regression on Y, with the difference being that the horizontal deviations from the points to the line are minimized rather than the vertical. Again, the first task is to bring the reliability function into a linear form. This step is exactly the same as in the regression on Y analysis and all the equations apply in this case too. The derivation from the previous analysis begins on the least squares fit part, where in this case we treat as the dependent variable and as the independent variable. The best-fitting straight line to the data, for regression on X (see Parameter Estimation), is the straight line:


The corresponding equations for  and
and
 are:
are:


and:


where:

and:

and the  values are again obtained from the median ranks.
values are again obtained from the median ranks.

Once  and
and
 are obtained, solve the linear equation for
are obtained, solve the linear equation for
 , which corresponds to:
, which corresponds to:
-
 Solving for the parameters from above equations, we get:
Solving for the parameters from above equations, we get:



and


The correlation coefficient is evaluated as before.
RRX Example
Again using the same data set from the probability plotting and RRY examples (with six failures at 16, 34, 53, 75, 93 and 120 hours), calculate the parameters using rank regression on X.
Solution
The same table constructed above for the RRY example can also be applied for RRX.
Using the values from this table we get:




or:


and:


or:


Therefore:


and:


The correlation coefficient is:

The results and the associated graph using Weibull++ are shown next. Note that the slight variation in the results is due to the number of significant figures used in the estimation of the median ranks. Weibull++ by default uses double precision accuracy when computing the median ranks.
3-Parameter Weibull Regression
When the MR versus  points plotted on the Weibull probability paper do not fall on a satisfactory straight line and the points fall on a curve, then a location parameter,
points plotted on the Weibull probability paper do not fall on a satisfactory straight line and the points fall on a curve, then a location parameter,
 , might exist which may straighten out these points. The goal in this case is to fit a curve, instead of a line, through the data points using nonlinear regression. The Gauss-Newton method can be used to solve for the parameters,
, might exist which may straighten out these points. The goal in this case is to fit a curve, instead of a line, through the data points using nonlinear regression. The Gauss-Newton method can be used to solve for the parameters,
 ,
,
 and
and
 , by performing a Taylor series expansion on
, by performing a Taylor series expansion on
 . Then the nonlinear model is approximated with linear terms and ordinary least squares are employed to estimate the parameters. This procedure is iterated until a satisfactory solution is reached.
. Then the nonlinear model is approximated with linear terms and ordinary least squares are employed to estimate the parameters. This procedure is iterated until a satisfactory solution is reached.

(Note that other shapes, particularly S shapes, might suggest the existence of more than one population. In these cases, the multiple population mixed Weibull distribution, may be more appropriate.)
When you use the 3-parameter Weibull distribution, Weibull++ calculates the value of
 by utilizing an optimized Nelder-Mead algorithm and adjusts the points by this value of
by utilizing an optimized Nelder-Mead algorithm and adjusts the points by this value of
 such that they fall on a straight line, and then plots both the adjusted and the original unadjusted points. To draw a curve through the original unadjusted points, if so desired, select Weibull 3P Line Unadjusted for Gamma from the
Show Plot Line submenu under the Plot Options menu. The returned estimations of the parameters are the same when selecting RRX or RRY. To display the unadjusted data points and line along with the adjusted data points and line, select
Show/Hide Items under the Plot Options menu and include the unadjusted data points and line as follows:
such that they fall on a straight line, and then plots both the adjusted and the original unadjusted points. To draw a curve through the original unadjusted points, if so desired, select Weibull 3P Line Unadjusted for Gamma from the
Show Plot Line submenu under the Plot Options menu. The returned estimations of the parameters are the same when selecting RRX or RRY. To display the unadjusted data points and line along with the adjusted data points and line, select
Show/Hide Items under the Plot Options menu and include the unadjusted data points and line as follows:
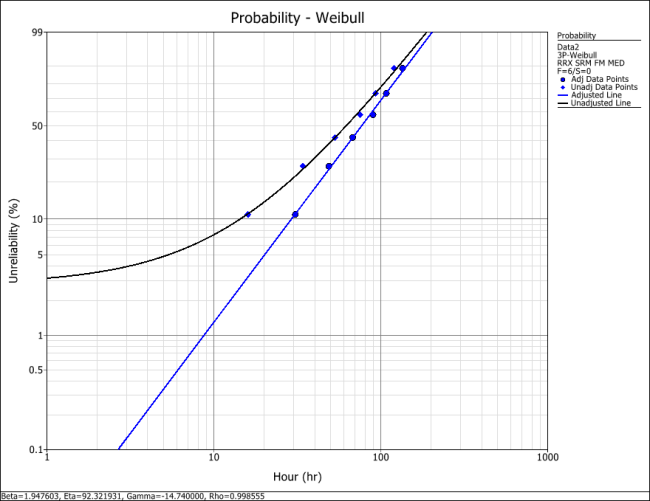
The results and the associated graph for the previous example using the 3-parameter Weibull case are shown next:
Maximum Likelihood Estimation
As outlined in
Parameter Estimation, maximum likelihood estimation works by developing a likelihood function based on the available data and finding the values of the parameter estimates that maximize the likelihood function. This can be achieved by using iterative methods to determine the parameter estimate values that maximize the likelihood function, but this can be rather difficult and time-consuming, particularly when dealing with the three-parameter distribution. Another method of finding the parameter estimates involves taking the partial derivatives of the likelihood function with respect to the parameters, setting the resulting equations equal to zero and solving simultaneously to determine the values of the parameter estimates. ( Note that MLE asymptotic properties do not hold when estimating
 using MLE, as discussed in Meeker and Escobar
[27].) The log-likelihood functions and associated partial derivatives used to determine maximum likelihood estimates for the Weibull distribution are covered in
Appendix D.
using MLE, as discussed in Meeker and Escobar
[27].) The log-likelihood functions and associated partial derivatives used to determine maximum likelihood estimates for the Weibull distribution are covered in
Appendix D.
MLE Example
One last time, use the same data set from the
probability plotting,
RRY and RRX examples (with six failures at 16, 34, 53, 75, 93 and 120 hours) and calculate the parameters using MLE.
Solution
In this case, we have non-grouped data with no suspensions or intervals, (i.e., complete data). The equations for the partial derivatives of the log-likelihood function are derived in an appendix and given next:


And:


Solving the above equations simultaneously we get:




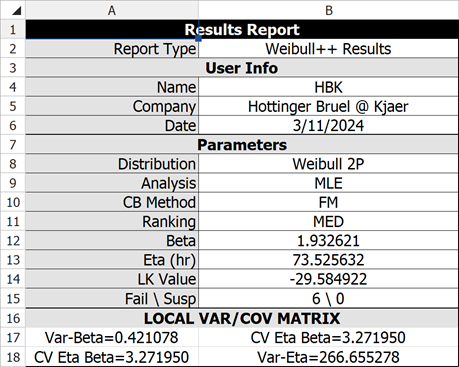
The variance/covariance matrix is found to be:

![{\displaystyle \left[{\begin{array}{ccc}{\hat {Var}}\left({\hat {\beta }}\right)=0.4211&{\hat {Cov}}({\hat {\beta }},{\hat {\eta }})=3.272\\{\hat {Cov}}({\hat {\beta }},{\hat {\eta }})=3.272&{\hat {Var}}\left({\hat {\eta }}\right)=266.646\end{array}}\right]\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/e5f6a97264cbf04788e3e6ef655e5f18f0366251)
The results and the associated plot using Weibull++ (MLE) are shown next.

You can view the variance/covariance matrix directly by clicking the Analysis Summary table in the control panel. Note that the decimal accuracy displayed and used is based on your individual Application Setup.
Unbiased MLE

It is well known that the MLE  is biased. The biasness will affect the accuracy of reliability prediction, especially when the number of failures are small. Weibull++ provides a simple way to correct the bias of MLE
is biased. The biasness will affect the accuracy of reliability prediction, especially when the number of failures are small. Weibull++ provides a simple way to correct the bias of MLE
 .
.
When there are no right censored observations in the data, the following equation provided by Hirose
[39] is used to calculated the unbiased
 .
.


where  is the number of failures.
is the number of failures.

When there are right censored observations in the data, the following equation provided by Ross
[40] is used to calculated the unbiased
 .
.


where  is the number of observations.
is the number of observations.

The software will use the above equations only when there are more than two failures in the data set.
For an example on how you might correct biased estimates, see also:
![]() Unbiasing Parameters in Weibull++
Unbiasing Parameters in Weibull++
Confidence Bounds
Fisher Matrix Confidence Bounds
One of the methods used by the application in estimating the different types of confidence bounds for Weibull data, the Fisher matrix method, is presented in this section. The complete derivations were presented in detail (for a general function) in Confidence Bounds.
Bounds on the Parameters
One of the properties of maximum likelihood estimators is that they are asymptotically normal, meaning that for large samples they are normally distributed. Additionally, since both the shape parameter estimate,
 , and the scale parameter estimate,
, and the scale parameter estimate,
 must be positive, thus
must be positive, thus
 and
and
 are treated as being normally distributed as well. The lower and upper bounds on the parameters are estimated from Nelson
[30]:
are treated as being normally distributed as well. The lower and upper bounds on the parameters are estimated from Nelson
[30]:







and:




where  is defined by:
is defined by:



If  is the confidence level, then
is the confidence level, then
 for the two-sided bounds and
for the two-sided bounds and
 for the one-sided bounds. The variances and covariances of
for the one-sided bounds. The variances and covariances of
 and
and
 are estimated from the inverse local Fisher matrix, as follows:
are estimated from the inverse local Fisher matrix, as follows:





Fisher Matrix Confidence Bounds and Regression Analysis
Note that the variance and covariance of the parameters are obtained from the inverse Fisher information matrix as described in this section. The local Fisher information matrix is obtained from the second partials of the likelihood function, by substituting the solved parameter estimates into the particular functions. This method is based on maximum likelihood theory and is derived from the fact that the parameter estimates were computed using maximum likelihood estimation methods. When one uses least squares or regression analysis for the parameter estimates, this methodology is theoretically then not applicable. However, if one assumes that the variance and covariance of the parameters will be similar ( One also assumes similar properties for both estimators.) regardless of the underlying solution method, then the above methodology can also be used in regression analysis.
The Fisher matrix is one of the methodologies that Weibull++ uses for both MLE and regression analysis. Specifically, Weibull++ uses the likelihood function and computes the local Fisher information matrix based on the estimates of the parameters and the current data. This gives consistent confidence bounds regardless of the underlying method of solution, (i.e., MLE or regression). In addition, Weibull++ checks this assumption and proceeds with it if it considers it to be acceptable. In some instances, Weibull++ will prompt you with an "Unable to Compute Confidence Bounds" message when using regression analysis. This is an indication that these assumptions were violated.
Bounds on Reliability
The bounds on reliability can easily be derived by first looking at the general extreme value distribution (EVD). Its reliability function is given by:


By transforming  and converting
and converting
 ,
,
 , the above equation becomes the Weibull reliability function:
, the above equation becomes the Weibull reliability function:





with:


set:


The reliability function now becomes:


The next step is to find the upper and lower bounds on
 . Using the equations derived in
Confidence Bounds, the bounds on reliability are then estimated from Nelson
[30]:
. Using the equations derived in
Confidence Bounds, the bounds on reliability are then estimated from Nelson
[30]:





where:


or:


The upper and lower bounds on reliability are:




Other Weibull Forms
Weibull++ makes the following assumptions/substitutions when using the three-parameter or one-parameter forms:
- For the 3-parameter case, substitute
 (and by definition
(and by definition
 ), instead of
), instead of
 . (Note that this is an approximation since it eliminates the third parameter and assumes that
. (Note that this is an approximation since it eliminates the third parameter and assumes that
 )
) - For the 1-parameter,
 thus:
thus:







Also note that the time axis (x-axis) in the three-parameter Weibull plot in Weibull++ is not
 but
but
 . This means that one must be cautious when obtaining confidence bounds from the plot. If one desires to estimate the confidence bounds on reliability for a given time
. This means that one must be cautious when obtaining confidence bounds from the plot. If one desires to estimate the confidence bounds on reliability for a given time
 from the adjusted plotted line, then these bounds should be obtained for a
from the adjusted plotted line, then these bounds should be obtained for a
 entry on the time axis.
entry on the time axis.




Bounds on Time
The bounds around the time estimate or reliable life estimate, for a given Weibull percentile (unreliability), are estimated by first solving the reliability equation with respect to time, as discussed in Lloyd and Lipow [24] and in Nelson [30]:






or:


where  .
.

The upper and lower bounds on are estimated from:


where:

or:

![{\displaystyle Var({\hat {u}})={\frac {1}{{\hat {\beta }}^{4}}}\left[\ln(-\ln R)\right]^{2}Var({\hat {\beta }})+{\frac {1}{{\hat {\eta }}^{2}}}Var({\hat {\eta }})+2\left(-{\frac {\ln(-\ln R)}{{\hat {\beta }}^{2}}}\right)\left({\frac {1}{\hat {\eta }}}\right)Cov\left({\hat {\beta }},{\hat {\eta }}\right)\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/c13115dc14a933dc968695a36ebcf3b77c119d92)
The upper and lower bounds are then found by:




Likelihood Ratio Confidence Bounds
As covered in
Confidence Bounds, the likelihood confidence bounds are calculated by finding values for
 and
and
 that satisfy:
that satisfy:




This equation can be rewritten as:


For complete data, the likelihood function for the Weibull distribution is given by:


For a given value of  , values for
, values for
 and
and
 can be found which represent the maximum and minimum values that satisfy the above equation. These represent the confidence bounds for the parameters at a confidence level
can be found which represent the maximum and minimum values that satisfy the above equation. These represent the confidence bounds for the parameters at a confidence level
 , where
, where
 for two-sided bounds and
for two-sided bounds and
 for one-sided.
for one-sided.




Similarly, the bounds on time and reliability can be found by substituting the Weibull reliability equation into the likelihood function so that it is in terms of
 and time or reliability, as discussed in
Confidence Bounds. The likelihood ratio equation used to solve for bounds on time (Type 1) is:
and time or reliability, as discussed in
Confidence Bounds. The likelihood ratio equation used to solve for bounds on time (Type 1) is:

![{\displaystyle L(\beta ,t)=\prod _{i=1}^{N}{\frac {\beta }{\left({\frac {t}{(-{\text{ln}}(R))^{\frac {1}{\beta }}}}\right)}}\cdot \left({\frac {x_{i}}{\left({\frac {t}{(-{\text{ ln}}(R))^{\frac {1}{\beta }}}}\right)}}\right)^{\beta -1}\cdot {\text{exp}}\left[-\left({\frac {x_{i}}{\left({\frac {t}{(-{\text{ln}}(R))^{\frac {1}{\beta }}}}\right)}}\right)^{\beta }\right]\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/aef03ea103a03f6bc781d304124bc35ed81cd5e1)
The likelihood ratio equation used to solve for bounds on reliability (Type 2) is:

![{\displaystyle L(\beta ,R)=\prod _{i=1}^{N}{\frac {\beta }{\left({\frac {t}{(-{\text{ln}}(R))^{\frac {1}{\beta }}}}\right)}}\cdot \left({\frac {x_{i}}{\left({\frac {t}{(-{\text{ ln}}(R))^{\frac {1}{\beta }}}}\right)}}\right)^{\beta -1}\cdot {\text{exp}}\left[-\left({\frac {x_{i}}{\left({\frac {t}{(-{\text{ln}}(R))^{\frac {1}{\beta }}}}\right)}}\right)^{\beta }\right]\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/2340ad516af37a7ba29805128b8280535b627ee0)
Bayesian Confidence Bounds
Bounds on Parameters
Bayesian Bounds use non-informative prior distributions for both parameters. From
Confidence Bounds, we know that if the prior distribution of
 and
and
 are independent, the posterior joint distribution of
are independent, the posterior joint distribution of
 and
and
 can be written as:
can be written as:


The marginal distribution of  is:
is:


where:  is the non-informative prior of
is the non-informative prior of
 .
.
 is the non-informative prior of
is the non-informative prior of
 . Using these non-informative prior distributions,
. Using these non-informative prior distributions,
 can be rewritten as:
can be rewritten as:





The one-sided upper bounds of  is:
is:


The one-sided lower bounds of  is:
is:


The two-sided bounds of  is:
is:


Same method is used to obtain the bounds of
 .
.
Bounds on Reliability


From the posterior distribution of  we have:
we have:


The above equation is solved numerically for
 . The same method can be used to calculate the one sided lower bounds and two-sided bounds on reliability.
. The same method can be used to calculate the one sided lower bounds and two-sided bounds on reliability.

Bounds on Time
From Confidence Bounds, we know that:


From the posterior distribution of  , we have:
, we have:


The above equation is solved numerically for
 . The same method can be applied to calculate one sided lower bounds and two-sided bounds on time.
. The same method can be applied to calculate one sided lower bounds and two-sided bounds on time.

Bayesian-Weibull Analysis
The Bayesian methods presented next are for the 2-parameter Weibull distribution. Bayesian concepts were introduced in
Parameter Estimation. This model considers prior knowledge on the shape ( ) parameter of the Weibull distribution when it is chosen to be fitted to a given set of data. There are many practical applications for this model, particularly when dealing with small sample sizes and some prior knowledge for the shape parameter is available. For example, when a test is performed, there is often a good understanding about the behavior of the failure mode under investigation, primarily through historical data. At the same time, most reliability tests are performed on a limited number of samples. Under these conditions, it would be very useful to use this prior knowledge with the goal of making more accurate predictions. A common approach for such scenarios is to use the 1-parameter Weibull distribution, but this approach is too deterministic, too absolute you may say (and you would be right). The Bayesian-Weibull model in Weibull++ (which is actually a true "WeiBayes" model, unlike the 1-parameter Weibull that is commonly referred to as such) offers an alternative to the 1-parameter Weibull, by including the variation and uncertainty that might have been observed in the past on the shape parameter. Applying Bayes's rule on the 2-parameter Weibull distribution and assuming the prior distributions of
) parameter of the Weibull distribution when it is chosen to be fitted to a given set of data. There are many practical applications for this model, particularly when dealing with small sample sizes and some prior knowledge for the shape parameter is available. For example, when a test is performed, there is often a good understanding about the behavior of the failure mode under investigation, primarily through historical data. At the same time, most reliability tests are performed on a limited number of samples. Under these conditions, it would be very useful to use this prior knowledge with the goal of making more accurate predictions. A common approach for such scenarios is to use the 1-parameter Weibull distribution, but this approach is too deterministic, too absolute you may say (and you would be right). The Bayesian-Weibull model in Weibull++ (which is actually a true "WeiBayes" model, unlike the 1-parameter Weibull that is commonly referred to as such) offers an alternative to the 1-parameter Weibull, by including the variation and uncertainty that might have been observed in the past on the shape parameter. Applying Bayes's rule on the 2-parameter Weibull distribution and assuming the prior distributions of
 and
and
 are independent, we obtain the following posterior
pdf:
are independent, we obtain the following posterior
pdf:


In this model,  is assumed to follow a noninformative prior distribution with the density function
is assumed to follow a noninformative prior distribution with the density function
 . This is called Jeffrey's prior, and is obtained by performing a logarithmic transformation on
. This is called Jeffrey's prior, and is obtained by performing a logarithmic transformation on
 . Specifically, since
. Specifically, since
 is always positive, we can assume that ln(
is always positive, we can assume that ln( ) follows a uniform distribution,
) follows a uniform distribution,
 ). Applying Jeffrey's rule as given in Gelman et al.
[9] which says "in general, an approximate non-informative prior is taken proportional to the square root of Fisher's information," yields
). Applying Jeffrey's rule as given in Gelman et al.
[9] which says "in general, an approximate non-informative prior is taken proportional to the square root of Fisher's information," yields
 .
.


The prior distribution of  , denoted as
, denoted as
 , can be selected from the following distributions: normal, lognormal, exponential and uniform. The procedure of performing a Bayesian-Weibull analysis is as follows:
, can be selected from the following distributions: normal, lognormal, exponential and uniform. The procedure of performing a Bayesian-Weibull analysis is as follows:

-
- Collect the times-to-failure data.
- Specify a prior distribution for
 (the prior for
(the prior for
 is assumed to be
is assumed to be
 ).
). - Obtain the posterior pdf from the above equation.

In other words, a distribution (the posterior pdf) is obtained, rather than a point estimate as in classical statistics (i.e., as in the parameter estimation methods described previously in this chapter). Therefore, if a point estimate needs to be reported, a point of the posterior pdf needs to be calculated. Typical points of the posterior distribution used are the mean (expected value) or median. In Weibull++, both options are available and can be chosen from the Analysis page, under the Results As area, as shown next.
The expected value of  is obtained by:
is obtained by:


Similarly, the expected value of  is obtained by:
is obtained by:


The median points are obtained by solving the following equations for
 and
and
 respectively:
respectively:




and:


Of course, other points of the posterior distribution can be calculated as well. For example, one may want to calculate the 10th percentile of the joint posterior distribution (w.r.t. one of the parameters). The procedure for obtaining other points of the posterior distribution is similar to the one for obtaining the median values, where instead of 0.5 the percentage of interest is given. This procedure actually provides the confidence bounds on the parameters, which in the Bayesian framework are called "Credible Bounds." However, since the engineering interpretation is the same, and to avoid confusion, we refer to them as confidence bounds in this reference and in Weibull++.
Posterior Distributions for Functions of Parameters
As explained in Parameter Estimation, in Bayesian analysis, all the functions of the parameters are distributed. In other words, a posterior distribution is obtained for functions such as reliability and failure rate, instead of point estimate as in classical statistics. Therefore, in order to obtain a point estimate for these functions, a point on the posterior distributions needs to be calculated. Again, the expected value (mean) or median value are used. It is important to note that the Median value is preferable and is the default in Weibull++. This is because the Median value always corresponds to the 50th percentile of the distribution. On the other hand, the Mean is not a fixed point on the distribution, which could cause issues, especially when comparing results across different data sets.
pdf of the Times-to-Failure
The posterior distribution of the failure time
 is given by:
is given by:


where:


For the pdf of the times-to-failure, only the expected value is calculated and reported in Weibull++.
Reliability
In order to calculate the median value of the reliability function, we first need to obtain posterior
pdf of the reliability. Since  is a function of
is a function of
 , the density functions of
, the density functions of
 and
and
 have the following relationship:
have the following relationship:



The median value of the reliability is obtained by solving the following equation w.r.t.




The expected value of the reliability at time
 is given by:
is given by:


where:


Failure Rate
The failure rate at time is given by:


where:


Bounds on Reliability for Bayesian-Weibull
The confidence bounds calculation under the Bayesian-Weibull analysis is very similar to the Bayesian Confidence Bounds method described in the previous section, with the exception that in the case of the Bayesian-Weibull Analysis the specified prior of
 is considered instead of an non-informative prior. The Bayesian one-sided upper bound estimate for
is considered instead of an non-informative prior. The Bayesian one-sided upper bound estimate for
 is given by:
is given by:


Using the posterior distribution, the following is obtained:


The above equation can be solved for
 . The Bayesian one-sided lower bound estimate for
. The Bayesian one-sided lower bound estimate for
 is given by:
is given by:




Using the posterior distribution, the following is obtained:


The above equation can be solved for
 . The Bayesian two-sided bounds estimate for
. The Bayesian two-sided bounds estimate for
 is given by:
is given by:

-
 which is equivalent to:
which is equivalent to:



and:


Using the same method for one-sided bounds,
 and
and
 can be computed.
can be computed.
Bounds on Time for Bayesian-Weibull
Following the same procedure described for bounds on Reliability, the bounds of time
 can be calculated, given
can be calculated, given
 . The Bayesian one-sided upper bound estimate for
. The Bayesian one-sided upper bound estimate for
 is given by:
is given by:



Using the posterior distribution, the following is obtained:


The above equation can be solved for
 . The Bayesian one-sided lower bound estimate for
. The Bayesian one-sided lower bound estimate for
 is given by:
is given by:




or:


The above equation can be solved for
 . The Bayesian two-sided lower bounds estimate for
. The Bayesian two-sided lower bounds estimate for
 is:
is:



which is equivalent to:


and:


Bayesian-Weibull Example
A manufacturer has tested prototypes of a modified product. The test was terminated at 2,000 hours, with only 2 failures observed from a sample size of 18. The following table shows the data.
| Number of State | State of F or S | State End Time |
|---|---|---|
| 1 | F | 1180 |
| 1 | F | 1842 |
| 16 | S | 2000 |
Because of the lack of failure data in the prototype testing, the manufacturer decided to use information gathered from prior tests on this product to increase the confidence in the results of the prototype testing. This decision was made because failure analysis indicated that the failure mode of the two failures is the same as the one that was observed in previous tests. In other words, it is expected that the shape of the distribution (beta) hasn't changed, but hopefully the scale (eta) has, indicating longer life. The 2-parameter Weibull distribution was used to model all prior tests results. The estimated beta ( ) parameters of the prior test results are as follows:
) parameters of the prior test results are as follows:
| Betas Obtained for Similar Mode |
|---|
| 1.7 |
| 2.1 |
| 2.4 |
| 3.1 |
| 3.5 |
Solution
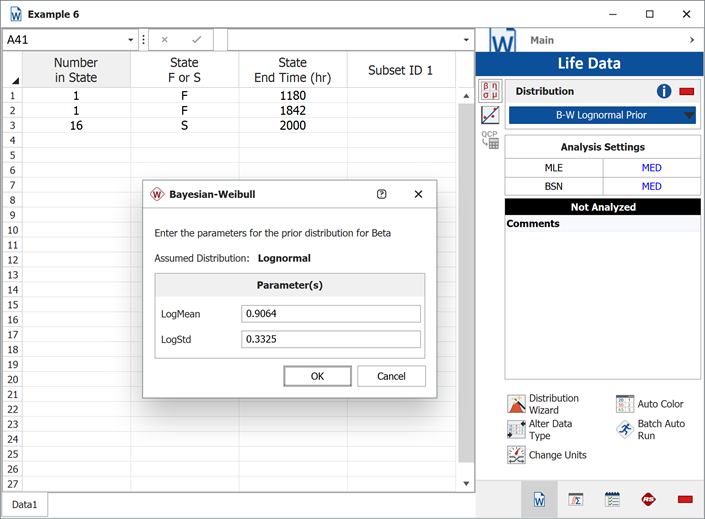
First, in order to fit the data to a Bayesian-Weibull model, a prior distribution for beta needs to be determined. Based on the beta values in the prior tests, the prior distribution for beta is found to be a lognormal distribution with
 ,
,
 . (The values of the parameters can be obtained by entering the beta values into a Weibull++ standard folio and analyzing it using the lognormal distribution and the RRX analysis method.)
. (The values of the parameters can be obtained by entering the beta values into a Weibull++ standard folio and analyzing it using the lognormal distribution and the RRX analysis method.)


Next, enter the data from the prototype testing into a standard folio. On the control panel, choose the Bayesian-Weibull > B-W Lognormal Prior distribution. Click Calculate and enter the parameters of the lognormal distribution, as shown next.
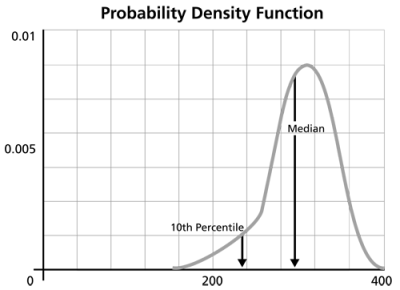
Click OK. The result is Beta (Median) = 2.361219 and Eta (Median) = 5321.631912 (by default Weibull++ returns the median values of the posterior distribution). Suppose that the reliability at 3,000 hours is the metric of interest in this example. Using the QCP, the reliability is calculated to be 76.97% at 3,000 hours. The following picture depicts the posterior pdf plot of the reliability at 3,000, with the corresponding median value as well as the 10th percentile value. The 10th percentile constitutes the 90% lower 1-sided bound on the reliability at 3,000 hours, which is calculated to be 50.77%.
The pdf of the times-to-failure data can be plotted in Weibull++, as shown next:
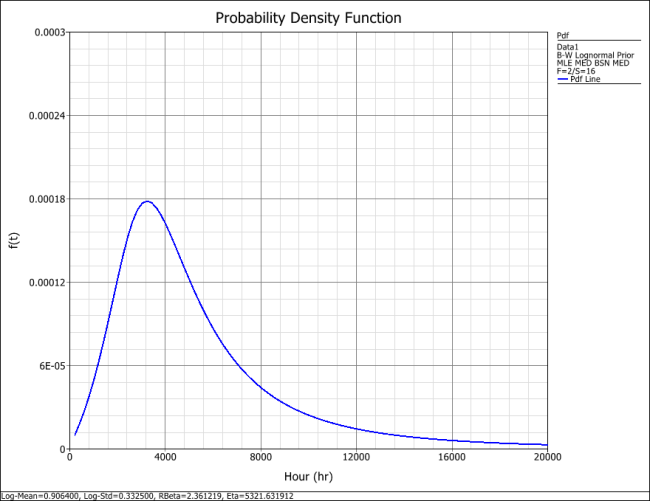
Weibull Distribution Examples
Median Rank Plot Example
In this example, we will determine the median rank value used for plotting the 6th failure from a sample size of 10. This example will use Weibull++'s Quick Statistical Reference (QSR) tool to show how the points in the plot of the following example are calculated.
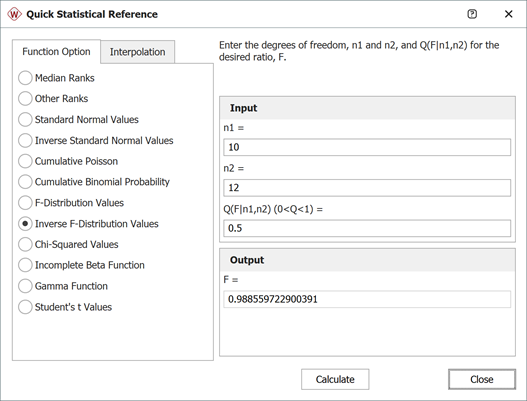
First, open the Quick Statistical Reference tool and select the Inverse F-Distribution Values option.
In this example, n1 = 10, j = 6, m = 2(10 - 6 + 1) = 10, and n2 = 2 x 6 = 12.
Thus, from the F-distribution rank equation:


Use the QSR to calculate the value of F0.5;10;12 = 0.9886, as shown next:
Consequently:


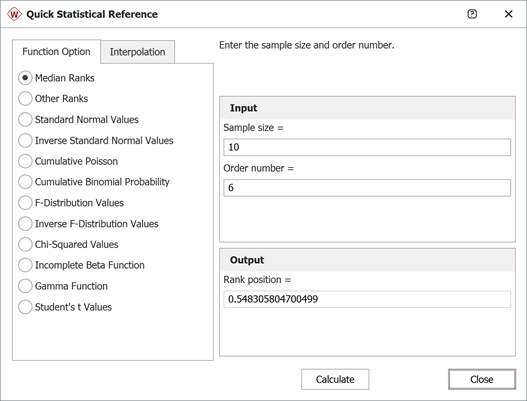
Another method is to use the Median Ranks option directly, which yields MR(%) = 54.8305%, as shown next:
Complete Data Example
Assume that 10 identical units (N = 10) are being reliability tested at the same application and operation stress levels. 6 of these units fail during this test after operating the following numbers of hours,
 : 150, 105, 83, 123, 64 and 46. The test is stopped at the 6th failure. Find the parameters of the Weibull
pdf that represents these data.
: 150, 105, 83, 123, 64 and 46. The test is stopped at the 6th failure. Find the parameters of the Weibull
pdf that represents these data.

Solution
Create a new Weibull++ standard folio that is configured for grouped times-to-failure data with suspensions.
Enter the data in the appropriate columns. Note that there are 4 suspensions, as only 6 of the 10 units were tested to failure (the next figure shows the data as entered). Use the 3-parameter Weibull and MLE for the calculations.
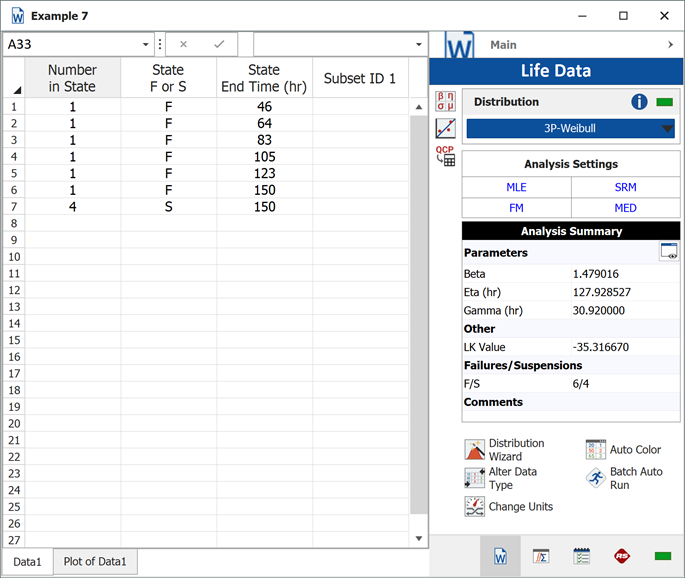
Plot the data.

Note that the original data points, on the curved line, were adjusted by subtracting 30.92 hours to yield a straight line as shown above.
Suspension Data Example
ACME company manufactures widgets, and it is currently engaged in reliability testing a new widget design. 19 units are being reliability tested, but due to the tremendous demand for widgets, units are removed from the test whenever the production cannot cover the demand. The test is terminated at the 67th day when the last widget is removed from the test. The following table contains the collected data.
| Data Point Index | State (F/S) | Time to Failure |
| 1 | F | 2 |
| 2 | S | 3 |
| 3 | F | 5 |
| 4 | S | 7 |
| 5 | F | 11 |
| 6 | S | 13 |
| 7 | S | 17 |
| 8 | S | 19 |
| 9 | F | 23 |
| 10 | F | 29 |
| 11 | S | 31 |
| 12 | F | 37 |
| 13 | S | 41 |
| 14 | F | 43 |
| 15 | S | 47 |
| 16 | S | 53 |
| 17 | F | 59 |
| 18 | S | 61 |
| 19 | S | 67 |
Solution
In this example, we see that the number of failures is less than the number of suspensions. This is a very common situation, since reliability tests are often terminated before all units fail due to financial or time constraints. Furthermore, some suspensions will be recorded when a failure occurs that is not due to a legitimate failure mode, such as operator error. In cases such as this, a suspension is recorded, since the unit under test cannot be said to have had a legitimate failure.
Enter the data into a Weibull++ standard folio that is configured for times-to-failure data with suspensions. The folio will appear as shown next:
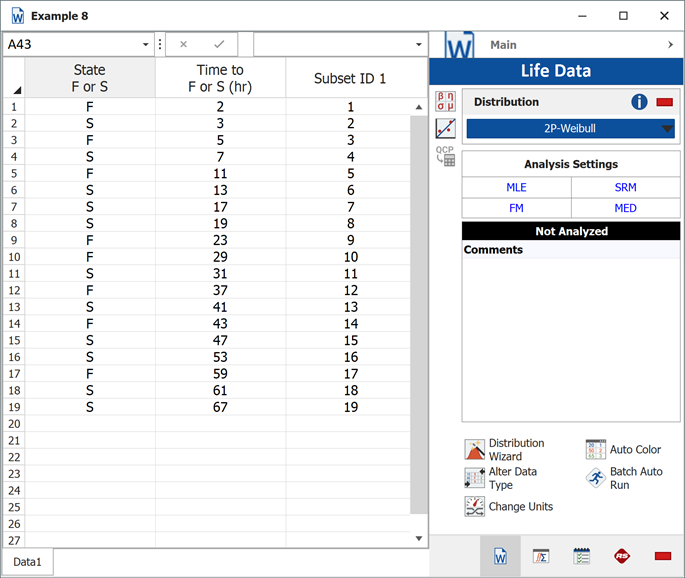
We will use the 2-parameter Weibull to solve this problem. The parameters using maximum likelihood are:


Using RRX:


Using RRY:


Interval Data Example
Suppose we have run an experiment with 8 units tested and the following is a table of their last inspection times and failure times:
| Data Point Index | Last Inspection | Failure Time |
| 1 | 30 | 32 |
| 2 | 32 | 35 |
| 3 | 35 | 37 |
| 4 | 37 | 40 |
| 5 | 42 | 42 |
| 6 | 45 | 45 |
| 7 | 50 | 50 |
| 8 | 55 | 55 |
Analyze the data using several different parameter estimation techniques and compare the results.
Solution
Enter the data into a Weibull++ standard folio that is configured for interval data. The data is entered as follows:
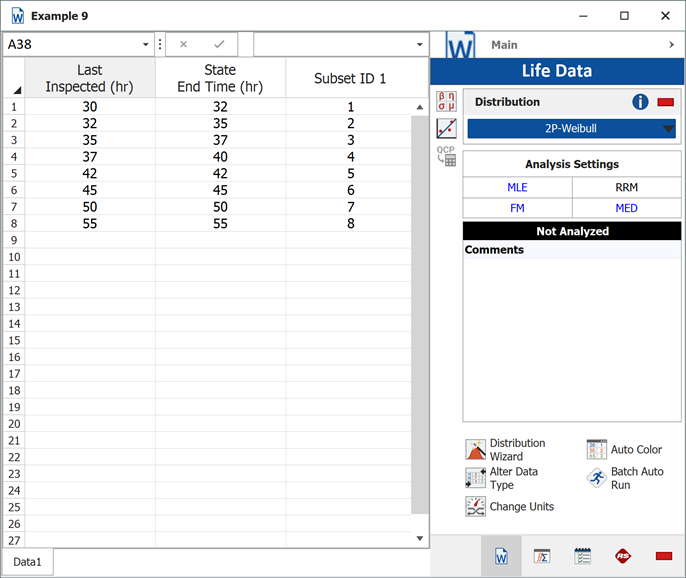
The computed parameters using maximum likelihood are:


Using RRX or rank regression on X:


Using RRY or rank regression on Y:


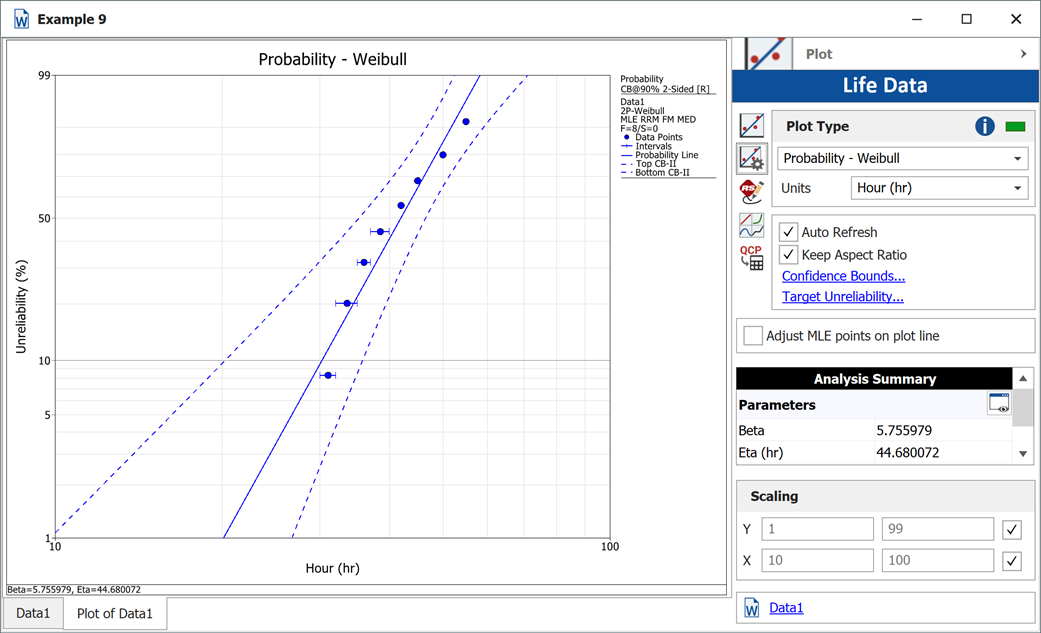
The plot of the MLE solution with the two-sided 90% confidence bounds is:
Mixed Data Types Example
From Dimitri Kececioglu, Reliability & Life Testing Handbook, Page 406. [20].
Estimate the parameters for the 3-parameter Weibull, for a sample of 10 units that are all tested to failure. The recorded failure times are 200; 370; 500; 620; 730; 840; 950; 1,050; 1,160 and 1,400 hours.
Published Results:
Published results (using probability plotting):
-
 ,
,
 ,
,




Computed Results in Weibull++
Weibull++ computed parameters for rank regression on X are:
-
 ,
,
 ,
,




The small difference between the published results and the ones obtained from Weibull++ are due to the difference in the estimation method. In the publication the parameters were estimated using probability plotting (i.e., the fitted line was "eye-balled"). In Weibull++, the parameters were estimated using non-linear regression (a more accurate, mathematically fitted line). Note that γ in this example is negative. This means that the unadjusted for γ line is concave up, as shown next.
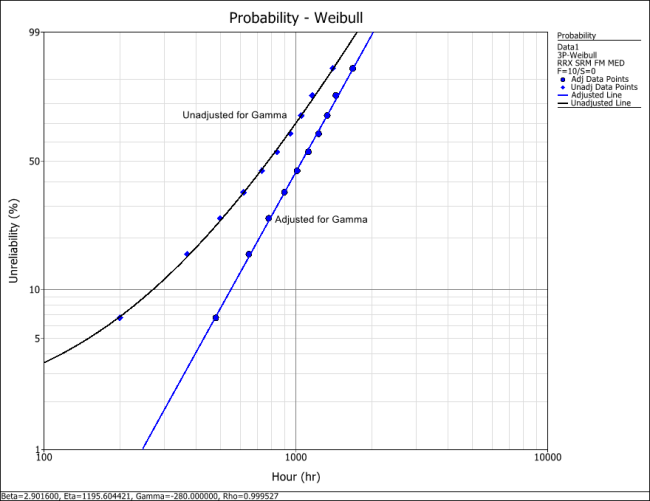
Weibull Distribution RRX Example
Assume that 6 identical units are being tested. The failure times are: 93, 34, 16, 120, 53 and 75 hours.
1. What is the unreliability of the units for a mission duration of 30 hours, starting the mission at age zero?
2. What is the reliability for a mission duration of 10 hours, starting the new mission at the age of T = 30 hours?
3. What is the longest mission that this product should undertake for a reliability of 90%?
Solution
1. First, we use Weibull++ to obtain the parameters using RRX.
Then, we investigate several methods of solution for this problem. The first, and more laborious, method is to extract the information directly from the plot. You may do this with either the screen plot in RS Draw or the printed copy of the plot. (When extracting information from the screen plot in RS Draw, note that the translated axis position of your mouse is always shown on the bottom right corner.)
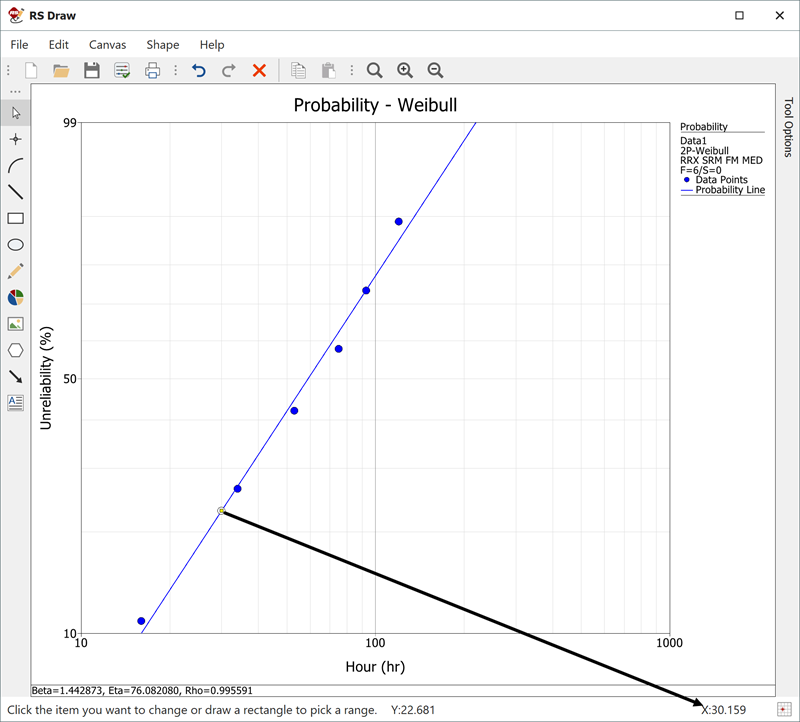
Using this first method, enter either the screen plot or the printed plot with T = 30 hours, go up vertically to the straight line fitted to the data, then go horizontally to the ordinate, and read off the result. A good estimate of the unreliability is 23%. (Also, the reliability estimate is 1.0 - 0.23 = 0.77 or 77%.)
The second method involves the use of the Quick Calculation Pad (QCP).
Select the Prob. of Failure calculation option and enter 30 hours in the Mission End Time field.
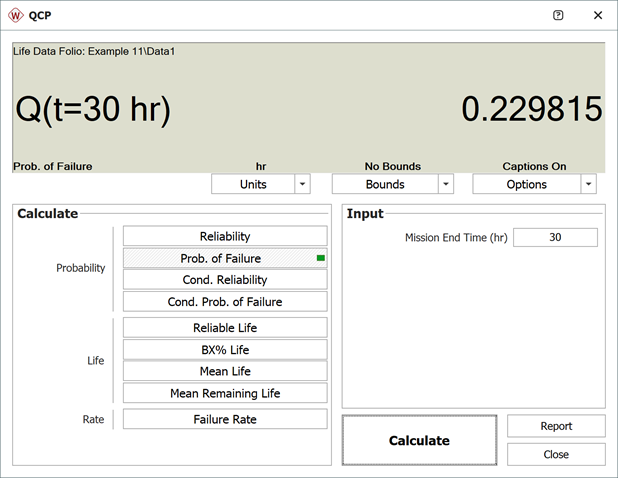
Note that the results in QCP vary according to the parameter estimation method used. The above results are obtained using RRX.
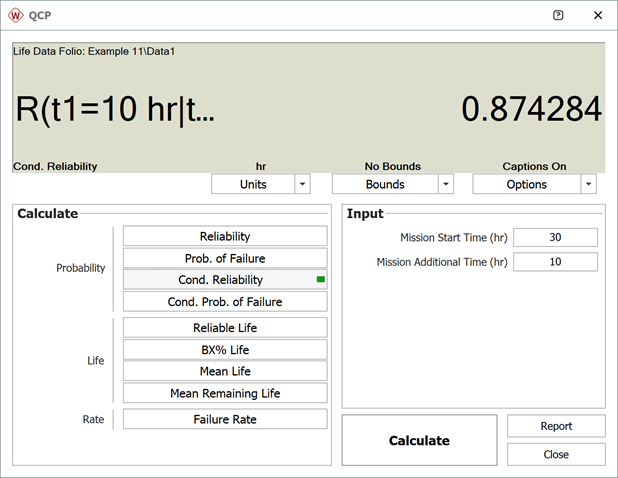
2. The conditional reliability is given by:


or:


Again, the QCP can provide this result directly and more accurately than the plot.
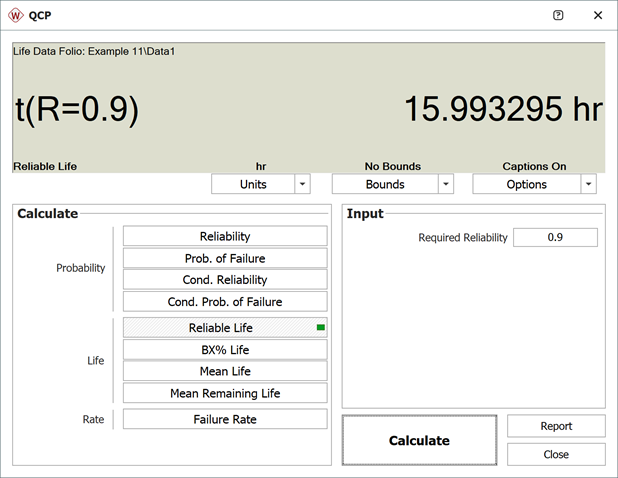
3. To use the QCP to solve for the longest mission that this product should undertake for a reliability of 90%, choose Reliable Life and enter 0.9 for the required reliability. The result is 15.9933 hours.
Benchmark with Published Examples
The following examples compare published results to computed results obtained with Weibull++.
Complete Data RRY Example
From Dimitri Kececioglu, Reliability & Life Testing Handbook, Page 418 [20].
Sample of 10 units, all tested to failure. The failures were recorded at 16, 34, 53, 75, 93, 120, 150, 191, 240 and 339 hours.
Published Results
Published Results (using Rank Regression on Y):


Computed Results in Weibull++
This same data set can be entered into a Weibull++ standard data sheet. Use RRY for the estimation method.
Weibull++ computed parameters for RRY are:


The small difference between the published results and the ones obtained from Weibull++ is due to the difference in the median rank values between the two (in the publication, median ranks are obtained from tables to 3 decimal places, whereas in Weibull++ they are calculated and carried out up to the 15th decimal point).
You will also notice that in the examples that follow, a small difference may exist between the published results and the ones obtained from Weibull++. This can be attributed to the difference between the computer numerical precision employed by Weibull++ and the lower number of significant digits used by the original authors. In most of these publications, no information was given as to the numerical precision used.
Suspension Data MLE Example
From Wayne Nelson, Fan Example, Applied Life Data Analysis, page 317 [30].
70 diesel engine fans accumulated 344,440 hours in service and 12 of them failed. A table of their life data is shown next (+ denotes non-failed units or suspensions, using Dr. Nelson's nomenclature). Evaluate the parameters with their two-sided 95% confidence bounds, using MLE for the 2-parameter Weibull distribution.
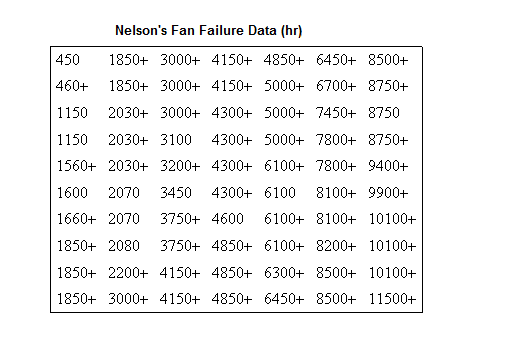
Published Results:
Weibull parameters (2P-Weibull, MLE):


Published 95% FM confidence limits on the parameters:


Published variance/covariance matrix:
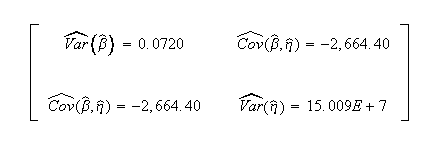
Note that Nelson expresses the results as multiples of 1,000 (or = 26.297, etc.). The published results were adjusted by this factor to correlate with Weibull++ results.
Computed Results in Weibull++
This same data set can be entered into a Weibull++ standard folio, using 2-parameter Weibull and MLE to calculate the parameter estimates.
You can also enter the data as given in table without grouping them by opening a data sheet configured for suspension data. Then click the Group Data icon and chose Group exactly identical values.
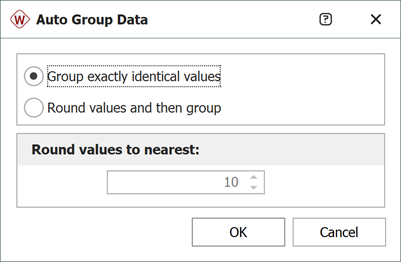
The data will be automatically grouped and put into a new grouped data sheet.
Weibull++ computed parameters for maximum likelihood are:


Weibull++ computed 95% FM confidence limits on the parameters:

Weibull++ computed/variance covariance matrix:
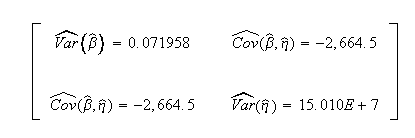
The two-sided 95% bounds on the parameters can be determined from the QCP. Calculate and then click Report to see the results.
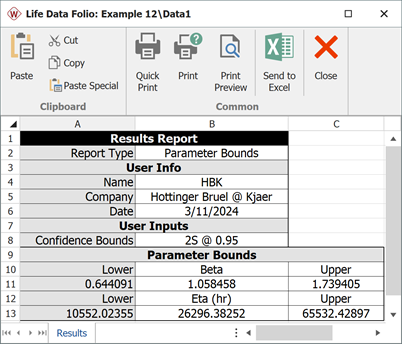
Interval Data MLE Example
From Wayne Nelson, Applied Life Data Analysis, Page 415 [30]. 167 identical parts were inspected for cracks. The following is a table of their last inspection times and times-to-failure:
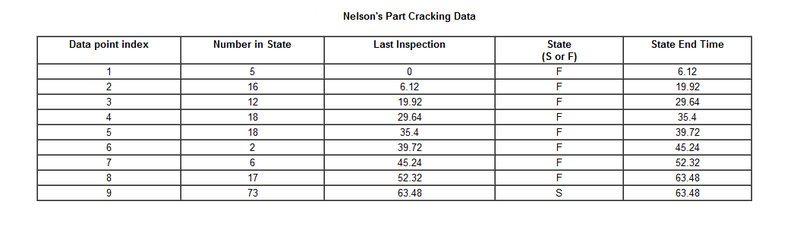
Published Results:
Published results (using MLE):


Published 95% FM confidence limits on the parameters:


Published variance/covariance matrix:
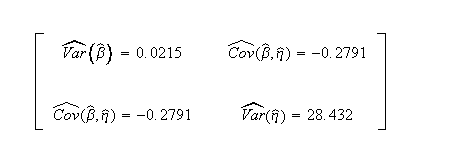
Computed Results in Weibull++
This same data set can be entered into a Weibull++ standard folio that's configured for grouped times-to-failure data with suspensions and interval data.
Weibull++ computed parameters for maximum likelihood are:


Weibull++ computed 95% FM confidence limits on the parameters:


Weibull++ computed/variance covariance matrix:
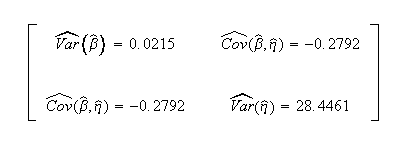
Grouped Suspension MLE Example
From Dallas R. Wingo, IEEE Transactions on Reliability Vol. R-22, No 2, June 1973, Pages 96-100.
Wingo uses the following times-to-failure: 37, 55, 64, 72, 74, 87, 88, 89, 91, 92, 94, 95, 97, 98, 100, 101, 102, 102, 105, 105, 107, 113, 117, 120, 120, 120, 122, 124, 126, 130, 135, 138, 182. In addition, the following suspensions are used: 4 at 70, 5 at 80, 4 at 99, 3 at 121 and 1 at 150.
Published Results (using MLE)


Computed Results in Weibull++

Note that you must select the Use True 3-P MLEoption in the Weibull++ Application Setup to replicate these results.
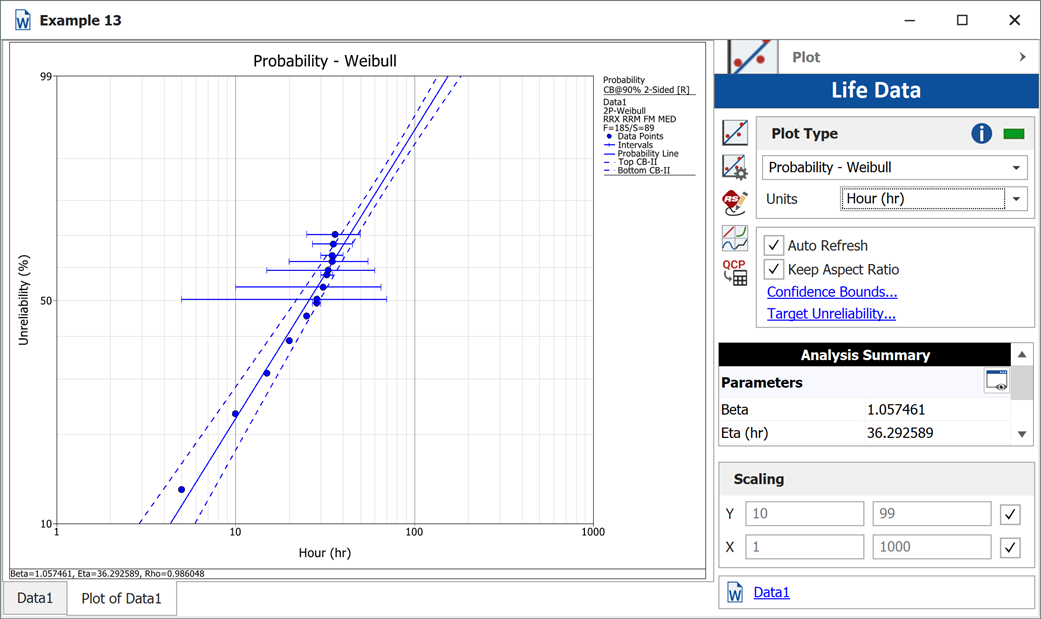
3-P Probability Plot Example
Suppose we want to model a left censored, right censored, interval, and complete data set, consisting of 274 units under test of which 185 units fail. The following table contains the data.
| Data Point Index | Number in State | Last Inspection | State (S or F) | State End Time |
| 1 | 2 | 5 | F | 5 |
| 2 | 23 | 5 | S | 5 |
| 3 | 28 | 0 | F | 7 |
| 4 | 4 | 10 | F | 10 |
| 5 | 7 | 15 | F | 15 |
| 6 | 8 | 20 | F | 20 |
| 7 | 29 | 20 | S | 20 |
| 8 | 32 | 0 | F | 22 |
| 9 | 6 | 25 | F | 25 |
| 10 | 4 | 27 | F | 30 |
| 11 | 8 | 30 | F | 35 |
| 12 | 5 | 30 | F | 40 |
| 13 | 9 | 27 | F | 45 |
| 14 | 7 | 25 | F | 50 |
| 15 | 5 | 20 | F | 55 |
| 16 | 3 | 15 | F | 60 |
| 17 | 6 | 10 | F | 65 |
| 18 | 3 | 5 | F | 70 |
| 19 | 37 | 100 | S | 100 |
| 20 | 48 | 0 | F | 102 |
Solution
Since standard ranking methods for dealing with these different data types are inadequate, we will want to use the ReliaSoft ranking method. This option is the default in Weibull++ when dealing with interval data. The filled-out standard folio is shown next:
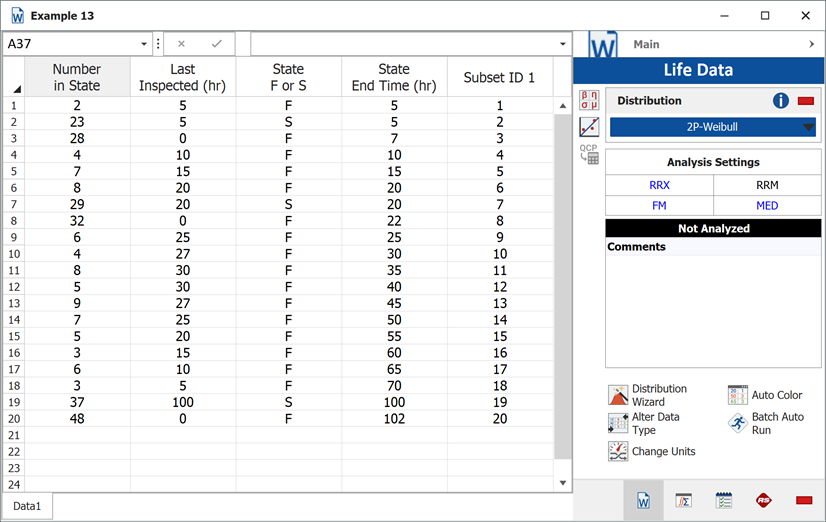
The computed parameters using MLE are:


Using RRX:


Using RRY:


The plot with the two-sided 90% confidence bounds for the rank regression on X solution is: