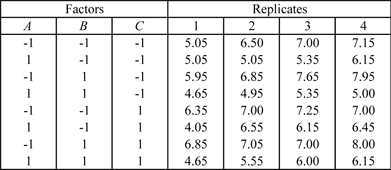
Two Level Factorial Experiments
Two level factorial experiments are factorial experiments in which each factor is investigated at only two levels. The early stages of experimentation usually involve the investigation of a large number of potential factors to discover the "vital few" factors. Two level factorial experiments are used during these stages to quickly filter out unwanted effects so that attention can then be focused on the important ones.
2^k Designs
The factorial experiments, where all combination of the levels of the factors are run, are usually referred to as
full factorial experiments. Full factorial two level experiments are also referred to as
 designs where
designs where
 denotes the number of factors being investigated in the experiment. In Weibull++ DOE folios, these designs are referred to as 2 Level Factorial Designs as shown in the figure below.
denotes the number of factors being investigated in the experiment. In Weibull++ DOE folios, these designs are referred to as 2 Level Factorial Designs as shown in the figure below.



A full factorial two level design with
 factors requires
factors requires
 runs for a single replicate. For example, a two level experiment with three factors will require
runs for a single replicate. For example, a two level experiment with three factors will require
 runs. The choice of the two levels of factors used in two level experiments depends on the factor; some factors naturally have two levels. For example, if gender is a factor, then male and female are the two levels. For other factors, the limits of the range of interest are usually used. For example, if temperature is a factor that varies from
runs. The choice of the two levels of factors used in two level experiments depends on the factor; some factors naturally have two levels. For example, if gender is a factor, then male and female are the two levels. For other factors, the limits of the range of interest are usually used. For example, if temperature is a factor that varies from
 to
to
 , then the two levels used in the
, then the two levels used in the
 design for this factor would be
design for this factor would be
 and
and
 .
.






The two levels of the factor in the
 design are usually represented as
design are usually represented as
 (for the first level) and
(for the first level) and
 (for the second level). Note that this representation is reversed from the coding used in
General Full Factorial Designs for the indicator variables that represent two level factors in ANOVA models. For ANOVA models, the first level of the factor was represented using a value of
(for the second level). Note that this representation is reversed from the coding used in
General Full Factorial Designs for the indicator variables that represent two level factors in ANOVA models. For ANOVA models, the first level of the factor was represented using a value of
 for the indicator variable, while the second level was represented using a value of
for the indicator variable, while the second level was represented using a value of
 . For details on the notation used for two level experiments refer to
Notation.
. For details on the notation used for two level experiments refer to
Notation.


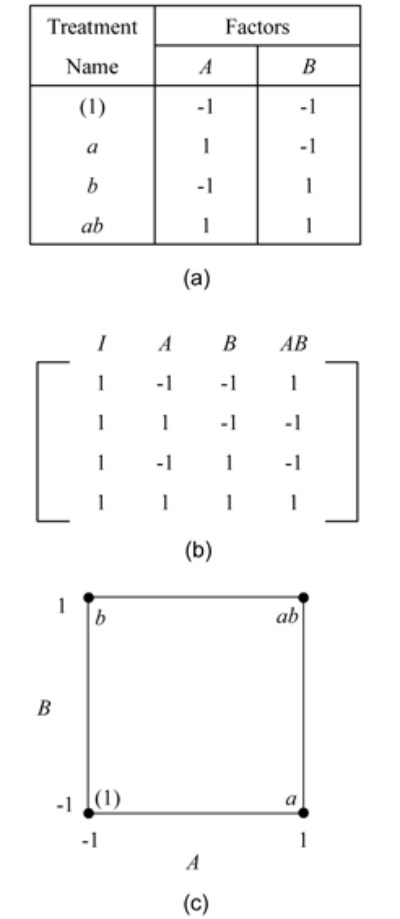
The 2^2 Design
The simplest of the two level factorial experiments is the
 design where two factors (say factor
design where two factors (say factor
 and factor
and factor
 ) are investigated at two levels. A single replicate of this design will require four runs (
) are investigated at two levels. A single replicate of this design will require four runs ( ) The effects investigated by this design are the two main effects,
) The effects investigated by this design are the two main effects,
 and
and
 and the interaction effect
and the interaction effect
 . The treatments for this design are shown in figure (a) below. In figure (a), letters are used to represent the treatments. The presence of a letter indicates the high level of the corresponding factor and the absence indicates the low level. For example, (1) represents the treatment combination where all factors involved are at the low level or the level represented by
. The treatments for this design are shown in figure (a) below. In figure (a), letters are used to represent the treatments. The presence of a letter indicates the high level of the corresponding factor and the absence indicates the low level. For example, (1) represents the treatment combination where all factors involved are at the low level or the level represented by
 ;
;
 represents the treatment combination where factor
represents the treatment combination where factor
 is at the high level or the level of
is at the high level or the level of
 , while the remaining factors (in this case, factor
, while the remaining factors (in this case, factor
 ) are at the low level or the level of
) are at the low level or the level of
 . Similarly,
. Similarly,
 represents the treatment combination where factor
represents the treatment combination where factor
 is at the high level or the level of
is at the high level or the level of
 , while factor
, while factor
 is at the low level and
is at the low level and
 represents the treatment combination where factors
represents the treatment combination where factors
 and
and
 are at the high level or the level of the 1. Figure (b) below shows the design matrix for the
are at the high level or the level of the 1. Figure (b) below shows the design matrix for the
 design. It can be noted that the sum of the terms resulting from the product of any two columns of the design matrix is zero. As a result the
design. It can be noted that the sum of the terms resulting from the product of any two columns of the design matrix is zero. As a result the
 design is an
orthogonal design. In fact, all
design is an
orthogonal design. In fact, all
 designs are orthogonal designs. This property of the
designs are orthogonal designs. This property of the
 designs offers a great advantage in the analysis because of the simplifications that result from orthogonality. These simplifications are explained later on in this chapter.
The
designs offers a great advantage in the analysis because of the simplifications that result from orthogonality. These simplifications are explained later on in this chapter.
The  design can also be represented geometrically using a square with the four treatment combinations lying at the four corners, as shown in figure (c) below.
design can also be represented geometrically using a square with the four treatment combinations lying at the four corners, as shown in figure (c) below.









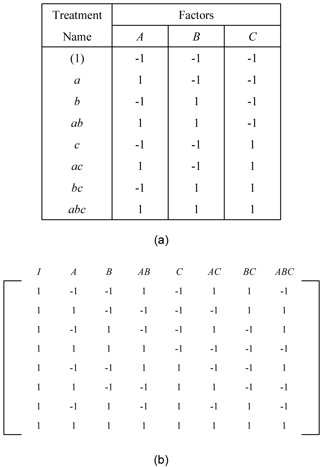
The 2^3 Design
The  design is a two level factorial experiment design with three factors (say factors
design is a two level factorial experiment design with three factors (say factors
 ,
,
 and
and
 ). This design tests three (
). This design tests three ( ) main effects,
) main effects,
 ,
,
 and
and
 ; three (
; three (
 ) two factor interaction effects,
) two factor interaction effects,
 ,
,
 ,
,
 ; and one (
; and one (
 ) three factor interaction effect,
) three factor interaction effect,
 . The design requires eight runs per replicate. The eight treatment combinations corresponding to these runs are
. The design requires eight runs per replicate. The eight treatment combinations corresponding to these runs are
 ,
,
 ,
,
 ,
,
 ,
,
 ,
,
 ,
,
 and
and
 . Note that the treatment combinations are written in such an order that factors are introduced one by one with each new factor being combined with the preceding terms. This order of writing the treatments is called the
standard order or Yates' order. The
. Note that the treatment combinations are written in such an order that factors are introduced one by one with each new factor being combined with the preceding terms. This order of writing the treatments is called the
standard order or Yates' order. The
 design is shown in figure (a) below. The design matrix for the
design is shown in figure (a) below. The design matrix for the
 design is shown in figure (b). The design matrix can be constructed by following the standard order for the treatment combinations to obtain the columns for the main effects and then multiplying the main effects columns to obtain the interaction columns.
design is shown in figure (b). The design matrix can be constructed by following the standard order for the treatment combinations to obtain the columns for the main effects and then multiplying the main effects columns to obtain the interaction columns.















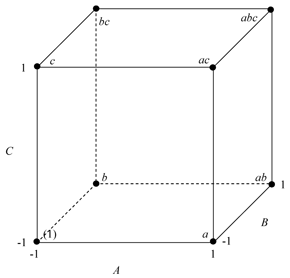
The  design can also be represented geometrically using a cube with the eight treatment combinations lying at the eight corners as shown in the figure above.
design can also be represented geometrically using a cube with the eight treatment combinations lying at the eight corners as shown in the figure above.
Analysis of 2^k Designs
The  designs are a special category of the factorial experiments where all the factors are at two levels. The fact that these designs contain factors at only two levels and are orthogonal greatly simplifies their analysis even when the number of factors is large. The use of
designs are a special category of the factorial experiments where all the factors are at two levels. The fact that these designs contain factors at only two levels and are orthogonal greatly simplifies their analysis even when the number of factors is large. The use of
 designs in investigating a large number of factors calls for a revision of the notation used previously for the ANOVA models. The case for revised notation is made stronger by the fact that the ANOVA and multiple linear regression models are identical for
designs in investigating a large number of factors calls for a revision of the notation used previously for the ANOVA models. The case for revised notation is made stronger by the fact that the ANOVA and multiple linear regression models are identical for
 designs because all factors are only at two levels. Therefore, the notation of the regression models is applied to the ANOVA models for these designs, as explained next.
designs because all factors are only at two levels. Therefore, the notation of the regression models is applied to the ANOVA models for these designs, as explained next.
Notation
Based on the notation used in General Full Factorial Designs, the ANOVA model for a two level factorial experiment with three factors would be as follows:


where:
 represents the overall mean
represents the overall mean represents the independent effect of the first factor (factor
represents the independent effect of the first factor (factor
 ) out of the two effects
) out of the two effects
 and
and

 represents the independent effect of the second factor (factor
represents the independent effect of the second factor (factor
 ) out of the two effects
) out of the two effects
 and
and

 represents the independent effect of the interaction
represents the independent effect of the interaction
 out of the other interaction effects
out of the other interaction effects represents the effect of the third factor (factor
represents the effect of the third factor (factor
 ) out of the two effects
) out of the two effects
 and
and

 represents the effect of the interaction
represents the effect of the interaction
 out of the other interaction effects
out of the other interaction effects represents the effect of the interaction
represents the effect of the interaction
 out of the other interaction effects
out of the other interaction effects-
 represents the effect of the interaction
represents the effect of the interaction
 out of the other interaction effects
out of the other interaction effects











and  is the random error term.
is the random error term.

The notation for a linear regression model having three predictor variables with interactions is:


The notation for the regression model is much more convenient, especially for the case when a large number of higher order interactions are present. In two level experiments, the ANOVA model requires only one indicator variable to represent each factor for both qualitative and quantitative factors. Therefore, the notation for the multiple linear regression model can be applied to the ANOVA model of the experiment that has all the factors at two levels. For example, for the experiment of the ANOVA model given above,
 can represent the overall mean instead of
can represent the overall mean instead of
 , and
, and
 can represent the independent effect,
can represent the independent effect,
 , of factor
, of factor
 . Other main effects can be represented in a similar manner. The notation for the interaction effects is much more simplified (e.g.,
. Other main effects can be represented in a similar manner. The notation for the interaction effects is much more simplified (e.g.,
 can be used to represent the three factor interaction effect,
can be used to represent the three factor interaction effect,
 ).
).




As mentioned earlier, it is important to note that the coding for the indicator variables for the ANOVA models of two level factorial experiments is reversed from the coding followed in
General Full Factorial Designs. Here
 represents the first level of the factor while
represents the first level of the factor while
 represents the second level. This is because for a two level factor a single variable is needed to represent the factor for both qualitative and quantitative factors. For quantitative factors, using
represents the second level. This is because for a two level factor a single variable is needed to represent the factor for both qualitative and quantitative factors. For quantitative factors, using
 for the first level (which is the low level) and 1 for the second level (which is the high level) keeps the coding consistent with the numerical value of the factors. The change in coding between the two coding schemes does not affect the analysis except that signs of the estimated effect coefficients will be reversed (i.e., numerical values of
for the first level (which is the low level) and 1 for the second level (which is the high level) keeps the coding consistent with the numerical value of the factors. The change in coding between the two coding schemes does not affect the analysis except that signs of the estimated effect coefficients will be reversed (i.e., numerical values of
 , obtained based on the coding of
General Full Factorial Designs, and
, obtained based on the coding of
General Full Factorial Designs, and
 , obtained based on the new coding, will be the same but their signs would be opposite).
, obtained based on the new coding, will be the same but their signs would be opposite).






In summary, the ANOVA model for the experiments with all factors at two levels is different from the ANOVA models for other experiments in terms of the notation in the following two ways:
- The notation of the regression models is used for the effect coefficients.
- The coding of the indicator variables is reversed.
Special Features
Consider the design matrix,  , for the
, for the
 design discussed above. The (
design discussed above. The ( )
)
 matrix is:
matrix is:




![{\displaystyle {{({{X}^{\prime }}X)}^{-1}}=\left[{\begin{matrix}0.125&0&0&0&0&0&0&0\\0&0.125&0&0&0&0&0&0\\0&0&0.125&0&0&0&0&0\\0&0&0&0.125&0&0&0&0\\0&0&0&0&0.125&0&0&0\\0&0&0&0&0&0.125&0&0\\0&0&0&0&0&0&0.125&0\\0&0&0&0&0&0&0&0.125\\\end{matrix}}\right]\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/d68fa7d4b63cf477e8c6af57f5d657a8c6e2614f)
Notice that, due to the orthogonal design of the
 matrix, the
matrix, the
 has been simplified to a diagonal matrix which can be written as:
has been simplified to a diagonal matrix which can be written as:



where  represents the identity matrix of the same order as the design matrix,
represents the identity matrix of the same order as the design matrix,
 . Since there are eight observations per replicate of the
. Since there are eight observations per replicate of the
 design, the
design, the
 '
'
 matrix for
matrix for
 replicates of this design can be written as:
replicates of this design can be written as:






The  matrix for any
matrix for any
 design can now be written as:
design can now be written as:


Then the variance-covariance matrix for the
 design is:
design is:


Note that the variance-covariance matrix for the
 design is also a diagonal matrix. Therefore, the estimated effect coefficients (
design is also a diagonal matrix. Therefore, the estimated effect coefficients ( ,
,
 ,
,
 etc.) for these designs are uncorrelated. This implies that the terms in the
etc.) for these designs are uncorrelated. This implies that the terms in the
 design (main effects, interactions) are independent of each other. Consequently, the extra sum of squares for each of the terms in these designs is independent of the sequence of terms in the model, and also independent of the presence of other terms in the model. As a result the sequential and partial sum of squares for the terms are identical for these designs and will always add up to the model sum of squares. Multicollinearity is also not an issue for these designs.
design (main effects, interactions) are independent of each other. Consequently, the extra sum of squares for each of the terms in these designs is independent of the sequence of terms in the model, and also independent of the presence of other terms in the model. As a result the sequential and partial sum of squares for the terms are identical for these designs and will always add up to the model sum of squares. Multicollinearity is also not an issue for these designs.


It can also be noted from the equation given above, that in addition to the
 matrix being diagonal, all diagonal elements of the
matrix being diagonal, all diagonal elements of the
 matrix are identical. This means that the variance (or its square root, the standard error) of all estimated effect coefficients are the same. The standard error,
matrix are identical. This means that the variance (or its square root, the standard error) of all estimated effect coefficients are the same. The standard error,
 , for all the coefficients is:
, for all the coefficients is:



This property is used to construct the normal probability plot of effects in
 designs and identify significant effects using graphical techniques. For details on the normal probability plot of effects in a Weibull++ DOE folio, refer to
Normal Probability Plot of Effects.
designs and identify significant effects using graphical techniques. For details on the normal probability plot of effects in a Weibull++ DOE folio, refer to
Normal Probability Plot of Effects.
Example
To illustrate the analysis of a full factorial
 design, consider a three factor experiment to investigate the effect of honing pressure, number of strokes and cycle time on the surface finish of automobile brake drums. Each of these factors is investigated at two levels. The honing pressure is investigated at levels of 200
design, consider a three factor experiment to investigate the effect of honing pressure, number of strokes and cycle time on the surface finish of automobile brake drums. Each of these factors is investigated at two levels. The honing pressure is investigated at levels of 200
 and 400
and 400
 , the number of strokes used is 3 and 5 and the two levels of the cycle time are 3 and 5 seconds. The design for this experiment is set up in a Weibull++ DOE folio as shown in the first two following figures. It is decided to run two replicates for this experiment. The surface finish data collected from each run (using randomization) and the complete design is shown in the third following figure. The analysis of the experiment data is explained next.
, the number of strokes used is 3 and 5 and the two levels of the cycle time are 3 and 5 seconds. The design for this experiment is set up in a Weibull++ DOE folio as shown in the first two following figures. It is decided to run two replicates for this experiment. The surface finish data collected from each run (using randomization) and the complete design is shown in the third following figure. The analysis of the experiment data is explained next.




The applicable model using the notation for
 designs is:
designs is:


where the indicator variable,
 represents factor
represents factor
 (honing pressure),
(honing pressure),
 represents the low level of 200
represents the low level of 200
 and
and
 represents the high level of 400
represents the high level of 400
 . Similarly,
. Similarly,
 and
and
 represent factors
represent factors
 (number of strokes) and
(number of strokes) and
 (cycle time), respectively.
(cycle time), respectively.
 is the overall mean, while
is the overall mean, while
 ,
,
 and
and
 are the effect coefficients for the main effects of factors
are the effect coefficients for the main effects of factors
 ,
,
 and
and
 , respectively.
, respectively.
 ,
,
 and
and
 are the effect coefficients for the
are the effect coefficients for the
 ,
,
 and
and
 interactions, while
interactions, while
 represents the
represents the
 interaction.
interaction.









If the subscripts for the run ( ;
;
 1 to 8) and replicates (
1 to 8) and replicates ( ;
;
 1,2) are included, then the model can be written as:
1,2) are included, then the model can be written as:






To investigate how the given factors affect the response, the following hypothesis tests need to be carried:




This test investigates the main effect of factor
 (honing pressure). The statistic for this test is:
(honing pressure). The statistic for this test is:


where  is the mean square for factor
is the mean square for factor
 and
and
 is the error mean square. Hypotheses for the other main effects,
is the error mean square. Hypotheses for the other main effects,
 and
and
 , can be written in a similar manner.
, can be written in a similar manner.






This test investigates the two factor interaction
 . The statistic for this test is:
. The statistic for this test is:


where  is the mean square for the interaction
is the mean square for the interaction
 and
and
 is the error mean square. Hypotheses for the other two factor interactions,
is the error mean square. Hypotheses for the other two factor interactions,
 and
and
 , can be written in a similar manner.
, can be written in a similar manner.





This test investigates the three factor interaction
 . The statistic for this test is:
. The statistic for this test is:


where  is the mean square for the interaction
is the mean square for the interaction
 and
and
 is the error mean square.
To calculate the test statistics, it is convenient to express the ANOVA model in the form
is the error mean square.
To calculate the test statistics, it is convenient to express the ANOVA model in the form
 .
.


Expression of the ANOVA Model as

In matrix notation, the ANOVA model can be expressed as:

where:

![{\displaystyle y=\left[{\begin{matrix}{{Y}_{11}}\\{{Y}_{21}}\\.\\{{Y}_{81}}\\{{Y}_{12}}\\.\\{{Y}_{82}}\\\end{matrix}}\right]=\left[{\begin{matrix}90\\90\\.\\90\\86\\.\\80\\\end{matrix}}\right]{\text{ }}X=\left[{\begin{matrix}1&-1&-1&1&-1&1&1&-1\\1&1&-1&-1&-1&-1&1&1\\.&.&.&.&.&.&.&.\\1&1&1&1&1&1&1&1\\1&-1&-1&1&-1&1&1&-1\\.&.&.&.&.&.&.&.\\1&1&1&1&1&1&1&1\\\end{matrix}}\right]\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/bdff4a84b23413ace1066edeb54e55811f385bb0)

![{\displaystyle \beta =\left[{\begin{matrix}{{\beta }_{0}}\\{{\beta }_{1}}\\{{\beta }_{2}}\\{{\beta }_{12}}\\{{\beta }_{3}}\\{{\beta }_{13}}\\{{\beta }_{23}}\\{{\beta }_{123}}\\\end{matrix}}\right]{\text{ }}\epsilon =\left[{\begin{matrix}{{\epsilon }_{11}}\\{{\epsilon }_{21}}\\.\\{{\epsilon }_{81}}\\{{\epsilon }_{12}}\\.\\.\\{{\epsilon }_{82}}\\\end{matrix}}\right]\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/a7e6494acef1fc231526a9386e46a9dca2a4668d)
Calculation of the Extra Sum of Squares for the Factors
Knowing the matrices  ,
,
 and
and
 , the extra sum of squares for the factors can be calculated. These are used to calculate the mean squares that are used to obtain the test statistics. Since the experiment design is orthogonal, the partial and sequential extra sum of squares are identical. The extra sum of squares for each effect can be calculated as shown next. As an example, the extra sum of squares for the main effect of factor
, the extra sum of squares for the factors can be calculated. These are used to calculate the mean squares that are used to obtain the test statistics. Since the experiment design is orthogonal, the partial and sequential extra sum of squares are identical. The extra sum of squares for each effect can be calculated as shown next. As an example, the extra sum of squares for the main effect of factor
 is:
is:



![{\displaystyle {\begin{aligned}S{{S}_{A}}=&Model{\text{ }}Sum{\text{ }}of{\text{ }}Squares-Sum{\text{ }}of{\text{ }}Squares{\text{ }}of{\text{ }}model{\text{ }}excluding{\text{ }}the{\text{ }}main{\text{ }}effect{\text{ }}of{\text{ }}A\\=&{{y}^{\prime }}[H-(1/16)J]y-{{y}^{\prime }}[{{H}_{{\tilde {\ }}A}}-(1/16)J]y\end{aligned}}\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/23d6953261cb8f7de93354a277cd756f49d6b2e2)
where  is the hat matrix and
is the hat matrix and
 is the matrix of ones. The matrix
is the matrix of ones. The matrix
 can be calculated using
can be calculated using
 where
where
 is the design matrix,
is the design matrix,
 , excluding the second column that represents the main effect of factor
, excluding the second column that represents the main effect of factor
 . Thus, the sum of squares for the main effect of factor
. Thus, the sum of squares for the main effect of factor
 is:
is:






![{\displaystyle {\begin{aligned}S{{S}_{A}}=&{{y}^{\prime }}[H-(1/16)J]y-{{y}^{\prime }}[{{H}_{{\tilde {\ }}A}}-(1/16)J]y\\=&654.4375-549.375\\=&105.0625\end{aligned}}\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/290fbd13d3fd0a7df5e177720868845acb88fde4)
Similarly, the extra sum of squares for the interaction effect
 is:
is:

![{\displaystyle {\begin{aligned}S{{S}_{AB}}=&{{y}^{\prime }}[H-(1/16)J]y-{{y}^{\prime }}[{{H}_{{\tilde {\ }}AB}}-(1/16)J]y\\=&654.4375-636.375\\=&18.0625\end{aligned}}\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/c0b3a65acf26ad9f79e727b3ec94d2b7832ff87c)
The extra sum of squares for other effects can be obtained in a similar manner.
Calculation of the Test Statistics
Knowing the extra sum of squares, the test statistic for the effects can be calculated. For example, the test statistic for the interaction
 is:
is:


where  is the mean square for the
is the mean square for the
 interaction and
interaction and
 is the error mean square. The
is the error mean square. The
 value corresponding to the statistic,
value corresponding to the statistic,
 , based on the
, based on the
 distribution with one degree of freedom in the numerator and eight degrees of freedom in the denominator is:
distribution with one degree of freedom in the numerator and eight degrees of freedom in the denominator is:





Assuming that the desired significance is 0.1, since
 value > 0.1, it can be concluded that the interaction between honing pressure and number of strokes does not affect the surface finish of the brake drums. Tests for other effects can be carried out in a similar manner. The results are shown in the ANOVA Table in the following figure. The values S, R-sq and R-sq(adj) in the figure indicate how well the model fits the data. The value of S represents the standard error of the model, R-sq represents the coefficient of multiple determination and R-sq(adj) represents the adjusted coefficient of multiple determination. For details on these values refer to
Multiple Linear Regression Analysis.
value > 0.1, it can be concluded that the interaction between honing pressure and number of strokes does not affect the surface finish of the brake drums. Tests for other effects can be carried out in a similar manner. The results are shown in the ANOVA Table in the following figure. The values S, R-sq and R-sq(adj) in the figure indicate how well the model fits the data. The value of S represents the standard error of the model, R-sq represents the coefficient of multiple determination and R-sq(adj) represents the adjusted coefficient of multiple determination. For details on these values refer to
Multiple Linear Regression Analysis.

Calculation of Effect Coefficients
The estimate of effect coefficients can also be obtained:

![{\displaystyle {\begin{aligned}{\hat {\beta }}=&{{({{X}^{\prime }}X)}^{-1}}{{X}^{\prime }}y\\=&\left[{\begin{matrix}86.4375\\2.5625\\-4.9375\\1.0625\\-1.0625\\2.4375\\-1.3125\\-0.1875\\\end{matrix}}\right]\end{aligned}}\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/945a38a4815366b5309edb4f0625cde21b4bb74f)

The coefficients and related results are shown in the Regression Information table above. In the table, the Effect column displays the effects, which are simply twice the coefficients. The Standard Error column displays the standard error,
 . The Low CI and High CI columns display the confidence interval on the coefficients. The interval shown is the 90% interval as the significance is chosen as 0.1. The T Value column displays the
. The Low CI and High CI columns display the confidence interval on the coefficients. The interval shown is the 90% interval as the significance is chosen as 0.1. The T Value column displays the
 statistic,
statistic,
 , corresponding to the coefficients. The P Value column displays the
, corresponding to the coefficients. The P Value column displays the
 value corresponding to the
value corresponding to the
 statistic. (For details on how these results are calculated, refer to
General Full Factorial Designs). Plots of residuals can also be obtained from the DOE folio to ensure that the assumptions related to the ANOVA model are not violated.
statistic. (For details on how these results are calculated, refer to
General Full Factorial Designs). Plots of residuals can also be obtained from the DOE folio to ensure that the assumptions related to the ANOVA model are not violated.


Model Equation
From the analysis results in the above figure within
calculation of effect coefficients section, it is seen that effects
 ,
,
 and
and
 are significant. In a DOE folio, the
are significant. In a DOE folio, the
 values for the significant effects are displayed in red in the ANOVA Table for easy identification. Using the values of the estimated effect coefficients, the model for the present
values for the significant effects are displayed in red in the ANOVA Table for easy identification. Using the values of the estimated effect coefficients, the model for the present
 design in terms of the coded values can be written as:
design in terms of the coded values can be written as:


To make the model hierarchical, the main effect,
 , needs to be included in the model (because the interaction
, needs to be included in the model (because the interaction
 is included in the model). The resulting model is:
is included in the model). The resulting model is:


This equation can be viewed in a DOE folio, as shown in the following figure, using the Show Analysis Summary icon in the Control Panel. The equation shown in the figure will match the hierarchical model once the required terms are selected using the Select Effects icon.

Replicated and Repeated Runs
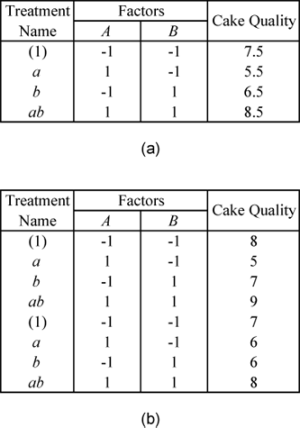
In the case of replicated experiments, it is important to note the difference between replicated runs and repeated runs. Both repeated and replicated runs are multiple response readings taken at the same factor levels. However, repeated runs are response observations taken at the same time or in succession. Replicated runs are response observations recorded in a random order. Therefore, replicated runs include more variation than repeated runs. For example, a baker, who wants to investigate the effect of two factors on the quality of cakes, will have to bake four cakes to complete one replicate of a
 design. Assume that the baker bakes eight cakes in all. If, for each of the four treatments of the
design. Assume that the baker bakes eight cakes in all. If, for each of the four treatments of the
 design, the baker selects one treatment at random and then bakes two cakes for this treatment at the same time then this is a case of two repeated runs. If, however, the baker bakes all the eight cakes randomly, then the eight cakes represent two sets of replicated runs.
For repeated measurements, the average values of the response for each treatment should be entered into a DOE folio as shown in the following figure (a) when the two cakes for a particular treatment are baked together. For replicated measurements, when all the cakes are baked randomly, the data is entered as shown in the following figure (b).
design, the baker selects one treatment at random and then bakes two cakes for this treatment at the same time then this is a case of two repeated runs. If, however, the baker bakes all the eight cakes randomly, then the eight cakes represent two sets of replicated runs.
For repeated measurements, the average values of the response for each treatment should be entered into a DOE folio as shown in the following figure (a) when the two cakes for a particular treatment are baked together. For replicated measurements, when all the cakes are baked randomly, the data is entered as shown in the following figure (b).
Unreplicated 2^k Designs
If a factorial experiment is run only for a single replicate then it is not possible to test hypotheses about the main effects and interactions as the error sum of squares cannot be obtained. This is because the number of observations in a single replicate equals the number of terms in the ANOVA model. Hence the model fits the data perfectly and no degrees of freedom are available to obtain the error sum of squares.
However, sometimes it is only possible to run a single replicate of the
 design because of constraints on resources and time. In the absence of the error sum of squares, hypothesis tests to identify significant factors cannot be conducted. A number of methods of analyzing information obtained from unreplicated
design because of constraints on resources and time. In the absence of the error sum of squares, hypothesis tests to identify significant factors cannot be conducted. A number of methods of analyzing information obtained from unreplicated
 designs are available. These include pooling higher order interactions, using the normal probability plot of effects or including center point replicates in the design.
designs are available. These include pooling higher order interactions, using the normal probability plot of effects or including center point replicates in the design.
Pooling Higher Order Interactions
One of the ways to deal with unreplicated
 designs is to use the sum of squares of some of the higher order interactions as the error sum of squares provided these higher order interactions can be assumed to be insignificant. By dropping some of the higher order interactions from the model, the degrees of freedom corresponding to these interactions can be used to estimate the error mean square. Once the error mean square is known, the test statistics to conduct hypothesis tests on the factors can be calculated.
designs is to use the sum of squares of some of the higher order interactions as the error sum of squares provided these higher order interactions can be assumed to be insignificant. By dropping some of the higher order interactions from the model, the degrees of freedom corresponding to these interactions can be used to estimate the error mean square. Once the error mean square is known, the test statistics to conduct hypothesis tests on the factors can be calculated.
Normal Probability Plot of Effects
Another way to use unreplicated  designs to identify significant effects is to construct the normal probability plot of the effects. As mentioned in
Special Features, the standard error for all effect coefficients in the
designs to identify significant effects is to construct the normal probability plot of the effects. As mentioned in
Special Features, the standard error for all effect coefficients in the
 designs is the same. Therefore, on a normal probability plot of effect coefficients, all non-significant effect coefficients (with
designs is the same. Therefore, on a normal probability plot of effect coefficients, all non-significant effect coefficients (with
 ) will fall along the straight line representative of the normal distribution, N(
) will fall along the straight line representative of the normal distribution, N( ). Effect coefficients that show large deviations from this line will be significant since they do not come from this normal distribution. Similarly, since effects
). Effect coefficients that show large deviations from this line will be significant since they do not come from this normal distribution. Similarly, since effects
 effect coefficients, all non-significant effects will also follow a straight line on the normal probability plot of effects. For replicated designs, the Effects Probability plot of a DOE folio plots the normalized effect values (or the T Values) on the standard normal probability line, N(0,1). However, in the case of unreplicated
effect coefficients, all non-significant effects will also follow a straight line on the normal probability plot of effects. For replicated designs, the Effects Probability plot of a DOE folio plots the normalized effect values (or the T Values) on the standard normal probability line, N(0,1). However, in the case of unreplicated
 designs,
designs,
 remains unknown since
remains unknown since
 cannot be obtained. Lenth's method is used in this case to estimate the variance of the effects. For details on Lenth's method, please refer to
Montgomery (2001). The DOE folio then uses this variance value to plot effects along the N(0, Lenth's effect variance) line. The
method is illustrated in the following example.
cannot be obtained. Lenth's method is used in this case to estimate the variance of the effects. For details on Lenth's method, please refer to
Montgomery (2001). The DOE folio then uses this variance value to plot effects along the N(0, Lenth's effect variance) line. The
method is illustrated in the following example.




Example
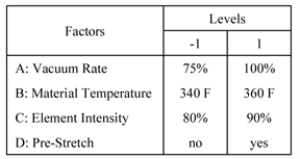
Vinyl panels, used as instrument panels in a certain automobile, are seen to develop defects after a certain amount of time. To investigate the issue, it is decided to carry out a two level factorial experiment. Potential factors to be investigated in the experiment are vacuum rate (factor
 ), material temperature (factor
), material temperature (factor
 ), element intensity (factor
), element intensity (factor
 ) and pre-stretch (factor
) and pre-stretch (factor
 ). The two levels of the factors used in the experiment are as shown in below.
). The two levels of the factors used in the experiment are as shown in below.

With a  design requiring 16 runs per replicate it is only feasible for the manufacturer to run a single replicate.
design requiring 16 runs per replicate it is only feasible for the manufacturer to run a single replicate.

The experiment design and data, collected as percent defects, are shown in the following figure. Since the present experiment design contains only a single replicate, it is not possible to obtain an estimate of the error sum of squares,
 . It is decided to use the normal probability plot of effects to identify the significant effects. The effect values for each term are obtained as shown in the following figure.
. It is decided to use the normal probability plot of effects to identify the significant effects. The effect values for each term are obtained as shown in the following figure.


Lenth's method uses these values to estimate the variance. As described in
[Lenth, 1989], if all effects are arranged in ascending order, using their absolute values, then
 is defined as 1.5 times the median value:
is defined as 1.5 times the median value:



Using  , the "pseudo standard error" (
, the "pseudo standard error" ( ) is calculated as 1.5 times the median value of all effects that are less than 2.5
) is calculated as 1.5 times the median value of all effects that are less than 2.5
 :
:



Using  as an estimate of the effect variance, the effect variance is 2.25. Knowing the effect variance, the normal probability plot of effects for the present unreplicated experiment can be constructed as shown in the following figure. The line on this plot is the line N(0, 2.25). The plot shows that the effects
as an estimate of the effect variance, the effect variance is 2.25. Knowing the effect variance, the normal probability plot of effects for the present unreplicated experiment can be constructed as shown in the following figure. The line on this plot is the line N(0, 2.25). The plot shows that the effects
 ,
,
 and the interaction
and the interaction
 do not follow the distribution represented by this line. Therefore, these effects are significant.
do not follow the distribution represented by this line. Therefore, these effects are significant.

The significant effects can also be identified by comparing individual effect values to the margin of error or the threshold value using the pareto chart (see the third following figure). If the required significance is 0.1, then:


The  statistic,
statistic,
 , is calculated at a significance of
, is calculated at a significance of
 (for the two-sided hypothesis) and degrees of freedom
(for the two-sided hypothesis) and degrees of freedom
 number of effects
number of effects
 . Thus:
. Thus:






The value of 4.534 is shown as the critical value line in the third following figure. All effects with absolute values greater than the margin of error can be considered to be significant. These effects are
 ,
,
 and the interaction
and the interaction
 . Therefore, the vacuum rate, the pre-stretch and their interaction have a significant effect on the defects of the vinyl panels.
. Therefore, the vacuum rate, the pre-stretch and their interaction have a significant effect on the defects of the vinyl panels.



Center Point Replicates
Another method of dealing with unreplicated
 designs that only have quantitative factors is to use replicated runs at the center point. The center point is the response corresponding to the treatment exactly midway between the two levels of all factors. Running multiple replicates at this point provides an estimate of pure error. Although running multiple replicates at any treatment level can provide an estimate of pure error, the other advantage of running center point replicates in the
designs that only have quantitative factors is to use replicated runs at the center point. The center point is the response corresponding to the treatment exactly midway between the two levels of all factors. Running multiple replicates at this point provides an estimate of pure error. Although running multiple replicates at any treatment level can provide an estimate of pure error, the other advantage of running center point replicates in the
 design is in checking for the presence of curvature. The test for curvature investigates whether the model between the response and the factors is linear and is discussed in
Center Pt. Replicates to Test Curvature.
design is in checking for the presence of curvature. The test for curvature investigates whether the model between the response and the factors is linear and is discussed in
Center Pt. Replicates to Test Curvature.
Example: Use Center Point to Get Pure Error
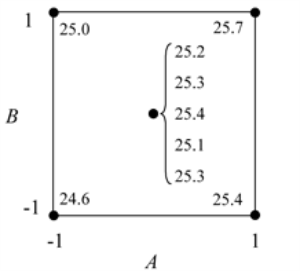
Consider a  experiment design to investigate the effect of two factors,
experiment design to investigate the effect of two factors,
 and
and
 , on a certain response. The energy consumed when the treatments of the
, on a certain response. The energy consumed when the treatments of the
 design are run is considerably larger than the energy consumed for the center point run (because at the center point the factors are at their middle levels). Therefore, the analyst decides to run only a single replicate of the design and augment the design by five replicated runs at the center point as shown in the following figure. The design properties for this experiment are shown in the second following figure. The complete experiment design is shown in the third following figure. The center points can be used in the identification of significant effects as shown next.
design are run is considerably larger than the energy consumed for the center point run (because at the center point the factors are at their middle levels). Therefore, the analyst decides to run only a single replicate of the design and augment the design by five replicated runs at the center point as shown in the following figure. The design properties for this experiment are shown in the second following figure. The complete experiment design is shown in the third following figure. The center points can be used in the identification of significant effects as shown next.
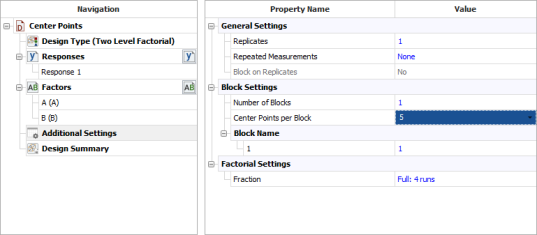
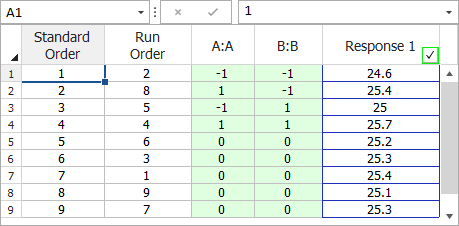
Since the present  design is unreplicated, there are no degrees of freedom available to calculate the error sum of squares. By augmenting this design with five center points, the response values at the center points,
design is unreplicated, there are no degrees of freedom available to calculate the error sum of squares. By augmenting this design with five center points, the response values at the center points,
 , can be used to obtain an estimate of pure error,
, can be used to obtain an estimate of pure error,
 . Let
. Let
 represent the average response for the five replicates at the center. Then:
represent the average response for the five replicates at the center. Then:







Then the corresponding mean square is:


Alternatively,  can be directly obtained by calculating the variance of the response values at the center points:
can be directly obtained by calculating the variance of the response values at the center points:



Once  is known, it can be used as the error mean square,
is known, it can be used as the error mean square,
 , to carry out the test of significance for each effect. For example, to test the significance of the main effect of factor
, to carry out the test of significance for each effect. For example, to test the significance of the main effect of factor
 the sum of squares corresponding to this effect is obtained in the usual manner by considering only the four runs of the original
the sum of squares corresponding to this effect is obtained in the usual manner by considering only the four runs of the original
 design.
design.


![{\displaystyle {\begin{aligned}S{{S}_{A}}=&{{y}^{\prime }}[H-(1/4)J]y-{{y}^{\prime }}[{{H}_{{\tilde {\ }}A}}-(1/4)J]y\\=&0.5625\end{aligned}}\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/759857d8fda54249a2157027566a9214ec9953d4)
Then, the test statistic to test the significance of the main effect of factor
 is:
is:


The  value corresponding to the statistic,
value corresponding to the statistic,
 , based on the
, based on the
 distribution with one degree of freedom in the numerator and eight degrees of freedom in the denominator is:
distribution with one degree of freedom in the numerator and eight degrees of freedom in the denominator is:



Assuming that the desired significance is 0.1, since
 value < 0.1, it can be concluded that the main effect of factor
value < 0.1, it can be concluded that the main effect of factor
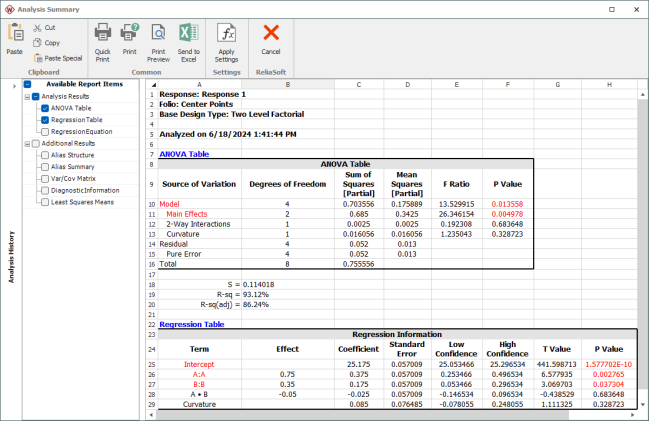
 significantly affects the response. This result is displayed in the ANOVA table as shown in the following figure. Test for the significance of other factors can be carried out in a similar manner.
significantly affects the response. This result is displayed in the ANOVA table as shown in the following figure. Test for the significance of other factors can be carried out in a similar manner.
Using Center Point Replicates to Test Curvature
Center point replicates can also be used to check for curvature in replicated or unreplicated
 designs. The test for curvature investigates whether the model between the response and the factors is linear. The way the DOE folio handles center point replicates is similar to its handling of blocks. The center point replicates are treated as an additional factor in the model. The factor is labeled as Curvature in the results of the DOE folio. If Curvature turns out to be a significant factor in the results, then this indicates the presence of curvature in the model.
designs. The test for curvature investigates whether the model between the response and the factors is linear. The way the DOE folio handles center point replicates is similar to its handling of blocks. The center point replicates are treated as an additional factor in the model. The factor is labeled as Curvature in the results of the DOE folio. If Curvature turns out to be a significant factor in the results, then this indicates the presence of curvature in the model.
Example: Use Center Point to Test Curvature
To illustrate the use of center point replicates in testing for curvature, consider again the data of the single replicate
 experiment from a preceding figure(labeled "
experiment from a preceding figure(labeled " design augmented by five center point runs"). Let
design augmented by five center point runs"). Let
 be the indicator variable to indicate if the run is a center point:
be the indicator variable to indicate if the run is a center point:




If  and
and
 are the indicator variables representing factors
are the indicator variables representing factors
 and
and
 , respectively, then the model for this experiment is:
, respectively, then the model for this experiment is:


To investigate the presence of curvature, the following hypotheses need to be tested:


The test statistic to be used for this test is:


where  is the mean square for Curvature and
is the mean square for Curvature and
 is the error mean square.
is the error mean square.

Calculation of the Sum of Squares
The  matrix and
matrix and
 vector for this experiment are:
vector for this experiment are:

![{\displaystyle X=\left[{\begin{matrix}1&1&-1&-1&1\\1&1&1&-1&-1\\1&1&-1&1&-1\\1&1&1&1&1\\1&0&0&0&0\\1&0&0&0&0\\1&0&0&0&0\\1&0&0&0&0\\1&0&0&0&0\\\end{matrix}}\right]{\text{ }}y=\left[{\begin{matrix}24.6\\25.4\\25.0\\25.7\\25.2\\25.3\\25.4\\25.1\\25.3\\\end{matrix}}\right]\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/29f000c984a4e30384f7d9fe6bd1c6609d7aa240)
The sum of squares can now be calculated. For example, the error sum of squares is:

![{\displaystyle {\begin{aligned}&S{{S}_{E}}=&{{y}^{\prime }}[I-H]y\\&=&0.052\end{aligned}}\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/ddcfc936245644948a632df4af0bd6263780bb79)
where  is the identity matrix and
is the identity matrix and
 is the hat matrix. It can be seen that this is equal to
is the hat matrix. It can be seen that this is equal to
 (the sum of squares due to pure error) because of the replicates at the center point, as obtained in the
example. The number of degrees of freedom associated with
(the sum of squares due to pure error) because of the replicates at the center point, as obtained in the
example. The number of degrees of freedom associated with
 ,
,
 is four. The extra sum of squares corresponding to the center point replicates (or Curvature) is:
is four. The extra sum of squares corresponding to the center point replicates (or Curvature) is:



![{\displaystyle {\begin{aligned}&S{{S}_{Curvature}}=&Model{\text{ }}Sum{\text{ }}of{\text{ }}Squares-\\&&Sum{\text{ }}of{\text{ }}Squares{\text{ }}of{\text{ }}model{\text{ }}excluding{\text{ }}the{\text{ }}center{\text{ }}point\\&=&{{y}^{\prime }}[H-(1/9)J]y-{{y}^{\prime }}[{{H}_{{\tilde {\ }}Curvature}}-(1/9)J]y\end{aligned}}\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/79c7b909f294cd53677b5ec323a25d78434fee4e)
where  is the hat matrix and
is the hat matrix and
 is the matrix of ones. The matrix
is the matrix of ones. The matrix
 can be calculated using
can be calculated using
 where
where
 is the design matrix,
is the design matrix,
 , excluding the second column that represents the center point. Thus, the extra sum of squares corresponding to Curvature is:
, excluding the second column that represents the center point. Thus, the extra sum of squares corresponding to Curvature is:




![{\displaystyle {\begin{aligned}&S{{S}_{Curvature}}=&{{y}^{\prime }}[H-(1/9)J]y-{{y}^{\prime }}[{{H}_{{\tilde {\ }}Center}}-(1/9)J]y\\&=&0.7036-0.6875\\&=&0.0161\end{aligned}}\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/a4126d2af0a4b2a1e7ad9763a01dc761b0c14bd1)
This extra sum of squares can be used to test for the significance of curvature. The corresponding mean square is:


Calculation of the Test Statistic
Knowing the mean squares, the statistic to check the significance of curvature can be calculated.


The  value corresponding to the statistic,
value corresponding to the statistic,
 , based on the
, based on the
 distribution with one degree of freedom in the numerator and four degrees of freedom in the denominator is:
distribution with one degree of freedom in the numerator and four degrees of freedom in the denominator is:



Assuming that the desired significance is 0.1, since
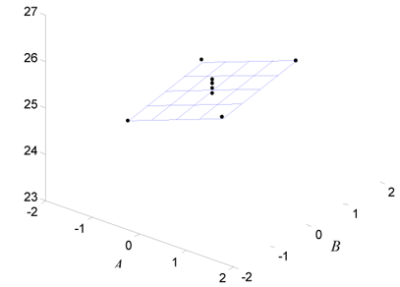
 value > 0.1, it can be concluded that curvature does not exist for this design. This results is shown in the ANOVA table in the figure above. The surface of the fitted model based on these results, along with the observed response values, is shown in the figure below.
value > 0.1, it can be concluded that curvature does not exist for this design. This results is shown in the ANOVA table in the figure above. The surface of the fitted model based on these results, along with the observed response values, is shown in the figure below.
Blocking in 2^k Designs
Blocking can be used in the  designs to deal with cases when replicates cannot be run under identical conditions. Randomized complete block designs that were discussed in
Randomization and Blocking in DOE for factorial experiments are also applicable here. At times, even with just two levels per factor, it is not possible to run all treatment combinations for one replicate of the experiment under homogeneous conditions. For example, each replicate of the
designs to deal with cases when replicates cannot be run under identical conditions. Randomized complete block designs that were discussed in
Randomization and Blocking in DOE for factorial experiments are also applicable here. At times, even with just two levels per factor, it is not possible to run all treatment combinations for one replicate of the experiment under homogeneous conditions. For example, each replicate of the
 design requires four runs. If each run requires two hours and testing facilities are available for only four hours per day, two days of testing would be required to run one complete replicate. Blocking can be used to separate the treatment runs on the two different days. Blocks that do not contain all treatments of a replicate are called incomplete blocks. In incomplete block designs, the block effect is confounded with certain effect(s) under investigation. For the
design requires four runs. If each run requires two hours and testing facilities are available for only four hours per day, two days of testing would be required to run one complete replicate. Blocking can be used to separate the treatment runs on the two different days. Blocks that do not contain all treatments of a replicate are called incomplete blocks. In incomplete block designs, the block effect is confounded with certain effect(s) under investigation. For the
 design assume that treatments
design assume that treatments
 and
and
 were run on the first day and treatments
were run on the first day and treatments
 and
and
 were run on the second day. Then, the incomplete block design for this experiment is:
were run on the second day. Then, the incomplete block design for this experiment is:

![{\displaystyle {\begin{matrix}{\text{Block 1}}&{}&{\text{Block 2}}\\\left[{\begin{matrix}(1)\\ab\\\end{matrix}}\right]&{}&\left[{\begin{matrix}a\\b\\\end{matrix}}\right]\\\end{matrix}}\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/477012c2a9e958aa9bd1e200d6c99035f5589208)
For this design the block effect may be calculated as:

![{\displaystyle {\begin{aligned}&Block{\text{ }}Effect=&Average{\text{ }}response{\text{ }}for{\text{ }}Block{\text{ }}1-\\&&Average{\text{ }}response{\text{ }}for{\text{ }}Block{\text{ }}2\\&=&{\frac {(1)+ab}{2}}-{\frac {a+b}{2}}\\&=&{\frac {1}{2}}[(1)+ab-a-b]\end{aligned}}\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/e780983ccecddd88d7be2ebf0d4883bd1ba887f0)
The  interaction effect is:
interaction effect is:

![{\displaystyle {\begin{aligned}&AB=&Average{\text{ }}response{\text{ }}at{\text{ }}{{A}_{\text{high}}}{\text{-}}{{B}_{\text{high}}}{\text{ }}and{\text{ }}{{A}_{\text{low}}}{\text{-}}{{B}_{\text{low}}}-\\&&Average{\text{ }}response{\text{ }}at{\text{ }}{{A}_{\text{low}}}{\text{-}}{{B}_{\text{high}}}{\text{ }}and{\text{ }}{{A}_{\text{high}}}{\text{-}}{{B}_{\text{low}}}\\&=&{\frac {ab+(1)}{2}}-{\frac {b+a}{2}}\\&=&{\frac {1}{2}}[(1)+ab-a-b]\end{aligned}}\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/a7c57ca5b920950b64d401297e1a67735a6e2ce5)
The two equations given above show that, in this design, the
 interaction effect cannot be distinguished from the block effect because the formulas to calculate these effects are the same. In other words, the
interaction effect cannot be distinguished from the block effect because the formulas to calculate these effects are the same. In other words, the
 interaction is said to be confounded with the block effect and it is not possible to say if the effect calculated based on these equations is due to the
interaction is said to be confounded with the block effect and it is not possible to say if the effect calculated based on these equations is due to the
 interaction effect, the block effect or both. In incomplete block designs some effects are always confounded with the blocks. Therefore, it is important to design these experiments in such a way that the important effects are not confounded with the blocks. In most cases, the experimenter can assume that higher order interactions are unimportant. In this case, it would better to use incomplete block designs that confound these effects with the blocks.
One way to design incomplete block designs is to use defining contrasts as shown next:
interaction effect, the block effect or both. In incomplete block designs some effects are always confounded with the blocks. Therefore, it is important to design these experiments in such a way that the important effects are not confounded with the blocks. In most cases, the experimenter can assume that higher order interactions are unimportant. In this case, it would better to use incomplete block designs that confound these effects with the blocks.
One way to design incomplete block designs is to use defining contrasts as shown next:


where the  s are the exponents for the factors in the effect that is to be confounded with the block effect and the
s are the exponents for the factors in the effect that is to be confounded with the block effect and the
 s are values based on the level of the
s are values based on the level of the
 the factor (in a treatment that is to be allocated to a block). For
the factor (in a treatment that is to be allocated to a block). For
 designs the
designs the
 s are either 0 or 1 and the
s are either 0 or 1 and the
 s have a value of 0 for the low level of the
s have a value of 0 for the low level of the
 th factor and a value of 1 for the high level of the factor in the treatment under consideration. As an example, consider the
th factor and a value of 1 for the high level of the factor in the treatment under consideration. As an example, consider the
 design where the interaction effect
design where the interaction effect
 is confounded with the block. Since there are two factors,
is confounded with the block. Since there are two factors,
 , with
, with
 representing factor
representing factor
 and
and
 representing factor
representing factor
 . Therefore:
. Therefore:







The value of  is one because the exponent of factor
is one because the exponent of factor
 in the confounded interaction
in the confounded interaction
 is one. Similarly, the value of
is one. Similarly, the value of
 is one because the exponent of factor
is one because the exponent of factor
 in the confounded interaction
in the confounded interaction
 is also one. Therefore, the defining contrast for this design can be written as:
is also one. Therefore, the defining contrast for this design can be written as:




Once the defining contrast is known, it can be used to allocate treatments to the blocks. For the
 design, there are four treatments
design, there are four treatments
 ,
,
 ,
,
 and
and
 . Assume that
. Assume that
 represents block 2 and
represents block 2 and
 represents block 1. In order to decide which block the treatment
represents block 1. In order to decide which block the treatment
 belongs to, the levels of factors
belongs to, the levels of factors
 and
and
 for this run are used. Since factor
for this run are used. Since factor
 is at the low level in this treatment,
is at the low level in this treatment,
 . Similarly, since factor
. Similarly, since factor
 is also at the low level in this treatment,
is also at the low level in this treatment,
 . Therefore:
. Therefore:






Note that the value of  used to decide the block allocation is "mod 2" of the original value. This value is obtained by taking the value of 1 for odd numbers and 0 otherwise. Based on the value of
used to decide the block allocation is "mod 2" of the original value. This value is obtained by taking the value of 1 for odd numbers and 0 otherwise. Based on the value of
 , treatment
, treatment
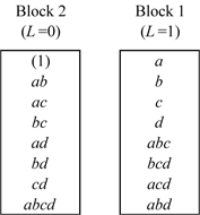
 is assigned to block 1. Other treatments can be assigned using the following calculations:
is assigned to block 1. Other treatments can be assigned using the following calculations:



Therefore, to confound the interaction
 with the block effect in the
with the block effect in the
 incomplete block design, treatments
incomplete block design, treatments
 and
and
 (with
(with
 ) should be assigned to block 2 and treatment combinations
) should be assigned to block 2 and treatment combinations
 and
and
 (with
(with
 ) should be assigned to block 1.
) should be assigned to block 1.
Example: Two Level Factorial Design with Two Blocks
This example illustrates how treatments can be allocated to two blocks for an unreplicated
 design. Consider the unreplicated
design. Consider the unreplicated
 design to investigate the four factors affecting the defects in automobile vinyl panels discussed in
Normal Probability Plot of Effects. Assume that the 16 treatments required for this experiment were run by two different operators with each operator conducting 8 runs. This experiment is an example of an incomplete block design. The analyst in charge of this experiment assumed that the interaction
design to investigate the four factors affecting the defects in automobile vinyl panels discussed in
Normal Probability Plot of Effects. Assume that the 16 treatments required for this experiment were run by two different operators with each operator conducting 8 runs. This experiment is an example of an incomplete block design. The analyst in charge of this experiment assumed that the interaction
 was not significant and decided to allocate treatments to the two operators so that the
was not significant and decided to allocate treatments to the two operators so that the
 interaction was confounded with the block effect (the two operators are the blocks). The allocation scheme to assign treatments to the two operators can be obtained as follows.
interaction was confounded with the block effect (the two operators are the blocks). The allocation scheme to assign treatments to the two operators can be obtained as follows.

The defining contrast for the  design where the
design where the
 interaction is confounded with the blocks is:
interaction is confounded with the blocks is:


The treatments can be allocated to the two operators using the values of the defining contrast. Assume that
 represents block 2 and
represents block 2 and
 represents block 1. Then the value of the defining contrast for treatment
represents block 1. Then the value of the defining contrast for treatment
 is:
is:


Therefore, treatment  should be assigned to Block 1 or the first operator. Similarly, for treatment
should be assigned to Block 1 or the first operator. Similarly, for treatment
 we have:
we have:


Therefore,  should be assigned to Block 2 or the second operator. Other treatments can be allocated to the two operators in a similar manner to arrive at the allocation scheme shown in the figure below.
In a DOE folio, to confound the
should be assigned to Block 2 or the second operator. Other treatments can be allocated to the two operators in a similar manner to arrive at the allocation scheme shown in the figure below.
In a DOE folio, to confound the  interaction for the
interaction for the
 design into two blocks, the number of blocks are specified as shown in the figure below. Then the interaction
design into two blocks, the number of blocks are specified as shown in the figure below. Then the interaction
 is entered in the Block Generator window (second following figure) which is available using the Block Generator button in the following figure. The design generated by the Weibull++ DOE folio is shown in the third of the following figures. This design matches the allocation scheme of the preceding figure.
is entered in the Block Generator window (second following figure) which is available using the Block Generator button in the following figure. The design generated by the Weibull++ DOE folio is shown in the third of the following figures. This design matches the allocation scheme of the preceding figure.



For the analysis of this design, the sum of squares for all effects are calculated assuming no blocking. Then, to account for blocking, the sum of squares corresponding to the
 interaction is considered as the sum of squares due to blocks and
interaction is considered as the sum of squares due to blocks and
 . In the DOE folio, this is done by displaying this sum of squares as the sum of squares due to the blocks. This is shown in the following figure where the sum of squares in question is obtained as 72.25 and is displayed against Block. The interaction ABCD, which is confounded with the blocks, is not displayed. Since the design is unreplicated, any of the methods to analyze unreplicated designs mentioned in
Unreplicated
. In the DOE folio, this is done by displaying this sum of squares as the sum of squares due to the blocks. This is shown in the following figure where the sum of squares in question is obtained as 72.25 and is displayed against Block. The interaction ABCD, which is confounded with the blocks, is not displayed. Since the design is unreplicated, any of the methods to analyze unreplicated designs mentioned in
Unreplicated
 designs have to be used to identify significant effects.
designs have to be used to identify significant effects.


Unreplicated 2^k Designs in 2^p Blocks
A single replicate of the  design can be run in up to
design can be run in up to
 blocks where
blocks where
 . The number of effects confounded with the blocks equals the degrees of freedom associated with the block effect.
. The number of effects confounded with the blocks equals the degrees of freedom associated with the block effect.


If two blocks are used (the block effect has two levels), then one ( effect is confounded with the blocks. If four blocks are used, then three (
effect is confounded with the blocks. If four blocks are used, then three ( ) effects are confounded with the blocks and so on. For example an unreplicated
) effects are confounded with the blocks and so on. For example an unreplicated
 design may be confounded in
design may be confounded in
 (four) blocks using two contrasts,
(four) blocks using two contrasts,
 and
and
 . Let
. Let
 and
and
 be the effects to be confounded with the blocks. Corresponding to these two effects, the contrasts are respectively:
be the effects to be confounded with the blocks. Corresponding to these two effects, the contrasts are respectively:







Based on the values of  and
and
 the treatments can be assigned to the four blocks as follows:
the treatments can be assigned to the four blocks as follows:


![{\displaystyle {\begin{matrix}{\text{Block 4}}&{}&{\text{Block 3}}&{}&{\text{Block 2}}&{}&{\text{Block 1}}\\{{L}_{1}}=0,{{L}_{2}}=0&{}&{{L}_{1}}=1,{{L}_{2}}=0&{}&{{L}_{1}}=0,{{L}_{2}}=1&{}&{{L}_{1}}=1,{{L}_{2}}=1\\{}&{}&{}&{}&{}&{}&{}\\\left[{\begin{matrix}(1)\\ac\\bd\\abcd\\\end{matrix}}\right]&{}&\left[{\begin{matrix}a\\c\\abd\\bcd\\\end{matrix}}\right]&{}&\left[{\begin{matrix}b\\abc\\d\\acd\\\end{matrix}}\right]&{}&\left[{\begin{matrix}ab\\bc\\ad\\cd\\\end{matrix}}\right]\\\end{matrix}}\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/96fc4cae9f466848e84ab0f8931111f8f1be8320)
Since the block effect has three degrees of freedom, three effects are confounded with the block effect. In addition to
 and
and
 , the third effect confounded with the block effect is their generalized interaction,
, the third effect confounded with the block effect is their generalized interaction,
 .
In general, when an unreplicated
.
In general, when an unreplicated  design is confounded in
design is confounded in
 blocks,
blocks,
 contrasts are needed (
contrasts are needed ( ).
).
 effects are selected to define these contrasts such that none of these effects are the generalized interaction of the others. The
effects are selected to define these contrasts such that none of these effects are the generalized interaction of the others. The
 blocks can then be assigned the treatments using the
blocks can then be assigned the treatments using the
 contrasts.
contrasts.
 effects, that are also confounded with the blocks, are then obtained as the generalized interaction of the
effects, that are also confounded with the blocks, are then obtained as the generalized interaction of the
 effects. In the statistical analysis of these designs, the sum of squares are computed as if no blocking were used. Then the block sum of squares is obtained by adding the sum of squares for all the effects confounded with the blocks.
effects. In the statistical analysis of these designs, the sum of squares are computed as if no blocking were used. Then the block sum of squares is obtained by adding the sum of squares for all the effects confounded with the blocks.



Example: 2 Level Factorial Design with Four Blocks
This example illustrates how a DOE folio obtains the sum of squares when treatments for an unreplicated
 design are allocated among four blocks. Consider again the unreplicated
design are allocated among four blocks. Consider again the unreplicated
 design used to investigate the defects in automobile vinyl panels presented in
Normal Probability Plot of Effects. Assume that the 16 treatments needed to complete the experiment were run by four operators. Therefore, there are four blocks. Assume that the treatments were allocated to the blocks using the generators mentioned in the previous section, i.e., treatments were allocated among the four operators by confounding the effects,
design used to investigate the defects in automobile vinyl panels presented in
Normal Probability Plot of Effects. Assume that the 16 treatments needed to complete the experiment were run by four operators. Therefore, there are four blocks. Assume that the treatments were allocated to the blocks using the generators mentioned in the previous section, i.e., treatments were allocated among the four operators by confounding the effects,
 and
and
 with the blocks. These effects can be specified as Block Generators as shown in the following figure. (The generalized interaction of these two effects, interaction
with the blocks. These effects can be specified as Block Generators as shown in the following figure. (The generalized interaction of these two effects, interaction
 , will also get confounded with the blocks.) The resulting design is shown in the second following figure and matches the allocation scheme obtained in the previous section.
, will also get confounded with the blocks.) The resulting design is shown in the second following figure and matches the allocation scheme obtained in the previous section.


The sum of squares in this case can be obtained by calculating the sum of squares for each of the effects assuming there is no blocking. Once the individual sum of squares have been obtained, the block sum of squares can be calculated. The block sum of squares is the sum of the sum of squares of effects,
 ,
,
 and
and
 , since these effects are confounded with the block effect. As shown in the second following figure, this sum of squares is 92.25 and is displayed against Block. The interactions
, since these effects are confounded with the block effect. As shown in the second following figure, this sum of squares is 92.25 and is displayed against Block. The interactions
 ,
,
 and
and
 , which are confounded with the blocks, are not displayed. Since the present design is unreplicated any of the methods to analyze unreplicated designs mentioned in
Unreplicated
, which are confounded with the blocks, are not displayed. Since the present design is unreplicated any of the methods to analyze unreplicated designs mentioned in
Unreplicated
 designs have to be used to identify significant effects.
designs have to be used to identify significant effects.


Variability Analysis
For replicated two level factorial experiments, the DOE folio provides the option of conducting variability analysis (using the Variability Analysis icon under the Data menu). The analysis is used to identify the treatment that results in the least amount of variation in the product or process being investigated. Variability analysis is conducted by treating the standard deviation of the response for each treatment of the experiment as an additional response. The standard deviation for a treatment is obtained by using the replicated response values at that treatment run. As an example, consider the
 design shown in the following figure where each run is replicated four times. A variability analysis can be conducted for this design. The DOE folio calculates eight standard deviation values corresponding to each treatment of the design (see second following figure). Then, the design is analyzed as an unreplicated
design shown in the following figure where each run is replicated four times. A variability analysis can be conducted for this design. The DOE folio calculates eight standard deviation values corresponding to each treatment of the design (see second following figure). Then, the design is analyzed as an unreplicated
 design with the standard deviations (displayed as Y Standard Deviation. in second following figure) as the response. The normal probability plot of effects identifies
design with the standard deviations (displayed as Y Standard Deviation. in second following figure) as the response. The normal probability plot of effects identifies
 as the effect that influences variability (see third figure following). Based on the effect coefficients obtained in the fourth figure following, the model for Y Std. is:
as the effect that influences variability (see third figure following). Based on the effect coefficients obtained in the fourth figure following, the model for Y Std. is:


Based on the model, the experimenter has two choices to minimize variability (by minimizing Y Std.). The first choice is that
 should be
should be
 (i.e.,
(i.e.,
 should be set at the high level) and
should be set at the high level) and
 should be
should be
 (i.e.,
(i.e.,
 should be set at the low level). The second choice is that
should be set at the low level). The second choice is that
 should be
should be
 (i.e.,
(i.e.,
 should be set at the low level) and
should be set at the low level) and
 should be
should be
 (i.e.,
(i.e.,
 should be set at the high level). The experimenter can select the most feasible choice.
should be set at the high level). The experimenter can select the most feasible choice.