Accelerated Life Testing and Weibull++
This chapter presents issues relevant to using the Weibull++ software package to analyze data collected in accelerated life tests. These issues include the types of data that can be analyzed and the types of plots that can be created to display analysis results.
Data and Data Types
Statistical models rely extensively on data to make predictions. In life data analysis, the models are the statistical distributions and the data are the life data or times-to-failure data of our product. In the case of accelerated life data analysis, the models are the life-stress relationships and the data are the times-to-failure data at a specific stress level.The accuracy of any prediction is directly proportional to the quality, accuracy and completeness of the supplied data. Good data, along with the appropriate model choice, usually results in good predictions. Bad or insufficient data will almost always result in bad predictions.
In the analysis of life data, we want to use all available data sets, which sometimes are incomplete or include uncertainty as to when a failure occurred. Life data can therefore be separated into two types: complete data (all information is available) or censored data (some of the information is missing). Each type is explained next.
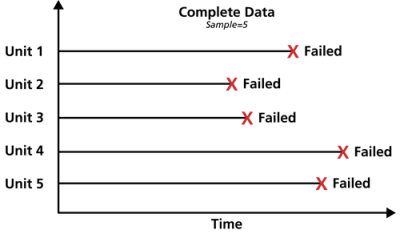
Complete Data
Complete data means that the value of each sample unit is observed or known. For example, if we had to compute the average test score for a sample of ten students, complete data would consist of the known score for each student. Likewise in the case of life data analysis, our data set (if complete) would be composed of the times-to-failure of all units in our sample. For example, if we tested five units and they all failed (and their times-to-failure were recorded), we would then have complete information as to the time of each failure in the sample.
Censored Data
In many cases, all of the units in the sample may not have failed (i.e., the event of interest was not observed) or the exact times-to-failure of all the units are not known. This type of data is commonly called censored data. There are three types of possible censoring schemes, right censored (also called suspended data), interval censored and left censored.
Right Censored (Suspension) Data
The most common case of censoring is what is referred to as right censored data, or suspended data. In the case of life data, these data sets are composed of units that did not fail. For example, if we tested five units and only three had failed by the end of the test, we would have right censored data (or suspension data) for the two units that did not failed. The term right censored implies that the event of interest (i.e., the time-to-failure) is to the right of our data point. In other words, if the units were to keep on operating, the failure would occur at some time after our data point (or to the right on the time scale).

Interval Censored Data
The second type of censoring is commonly called interval censored data. Interval censored data reflects uncertainty as to the exact times the units failed within an interval. This type of data frequently comes from tests or situations where the objects of interest are not constantly monitored. For example, if we are running a test on five units and inspecting them every 100 hours, we only know that a unit failed or did not fail between inspections. Specifically, if we inspect a certain unit at 100 hours and find it operating, and then perform another inspection at 200 hours to find that the unit is no longer operating, then the only information we have is that the unit failed at some point in the interval between 100 and 200 hours. This type of censored data is also called inspection data by some authors.
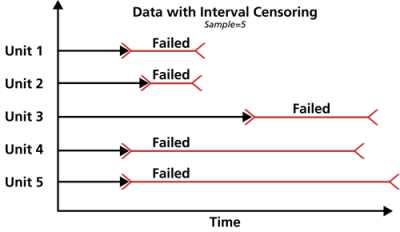
It is generally recommended to avoid interval censored data because they are less informative compared to complete data. However, there are cases when interval data are unavoidable due to the nature of the product, the test and the test equipment. In those cases, caution must be taken to set the inspection intervals to be short enough to observe the spread of the failures. For example, if the inspection interval is too long, all the units in the test may fail within that interval, and thus no failure distribution could be obtained.
In the case of accelerated life tests, the data set affects the accuracy of the fitted life-stress relationship, and subsequently, the extrapolation to Use Stress conditions. In this case, inspection intervals should be chosen according to the expected acceleration factor at each stress level, and therefore these intervals will be of different lengths for each stress level.
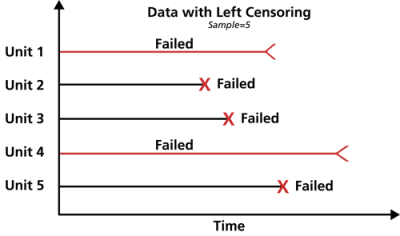
Left Censored Data
The third type of censoring is similar to the interval censoring and is called left censored data. In left censored data, a failure time is only known to be before a certain time. For instance, we may know that a certain unit failed sometime before 100 hours but not exactly when. In other words, it could have failed any time between 0 and 100 hours. This is identical to interval censored data in which the starting time for the interval is zero.
Grouped Data Analysis
In the standard folio, data can be entered individually or in groups. Grouped data analysis is used for tests in which groups of units possess the same time-to-failure or in which groups of units were suspended at the same time. We highly recommend entering redundant data in groups. Grouped data speeds data entry by the user and significantly speeds up the calculations.
A Note about Complete and Suspension Data
Depending on the event that we want to measure, data type classification (i.e., complete or suspension) can be open to interpretation. For example, under certain circumstances, and depending on the question one wishes to answer, a specimen that has failed might be classified as a suspension for analysis purposes. To illustrate this, consider the following times-to-failure data for a product that can fail due to modes A, B and C:
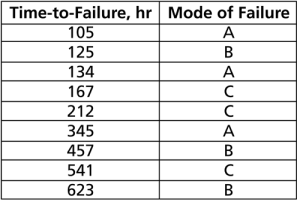
If the objective of the analysis is to determine the probability of failure of the product, regardless of the mode responsible for the failure, we would analyze the data with all data entries classified as failures (complete data). However, if the objective of the analysis is to determine the probability of failure of the product due to Mode A only, we would then choose to treat failures due to Modes B or C as suspension (right censored) data. Those data points would be treated as suspension data with respect to Mode A because the product operated until the recorded time without failure due to Mode A.
Fractional Failures
After the completion of a reliability test or after failures are observed in the field, a redesign can be implemented to improve a product's reliability. After the redesign, and before new failure data become available, it is often times desirable to"adjust" the reliability that was calculated from the previous design and take "credit" for this theoretical improvement. This can be achieved with fractional failures. Using past experience to estimate the effectiveness of a corrective action or redesign, an analysis can take credit for this improvement by adjusting the failure count. Therefore, if a corrective action on a failure mode is believed to be 70% effective, then the failure count can be reduced from 1 to 0.3 to reflect the effectiveness of the corrective action.
For example, consider the following data set.
| Number in State | State F or S | State End Time (Hr) |
|---|---|---|
| 1 | F | 105 |
| 0.4 | F | 168 |
| 1 | F | 220 |
| 1 | F | 290 |
| 1 | F | 410 |
In this case, a design change has been implemented for the failure mode that occurred at 168 hours and is assumed to be 60% effective. In the background, Weibull++ converts this data set to:
| Number in State | State F or S | State End Time (Hr) |
|---|---|---|
| 1 | F | 105 |
| 0.4 | F | 168 |
| 0.6 | S | 168 |
| 1 | F | 220 |
| 1 | F | 290 |
| 1 | F | 410 |
If Rank Regression is used to estimate distribution parameters, the median ranks for the previous data set are calculated as follows:
| Number in State | State F or S | State End Time (Hr) | MON | Median Rank (%) |
|---|---|---|---|---|
| 1 | F | 105 | 1 | 12.945 |
| 0.4 | F | 168 | 20.267 | |
| 0.6 | S | 168 | - | - |
| 1 | F | 220 | 2.55 | 41.616 |
| 1 | F | 290 | 3.7 | 63.039 |
| 1 | F | 410 | 4.85 | 84.325 |
Given this information, the standard Rank Regression procedure is then followed to estimate parameters.
If Maximum Likelihood Estimation (MLE) is used to estimate distribution parameters, the grouped data likelihood function is used with the number in group being a non-integer value.
Example
A component underwent a reliability test. 12 samples were run to failure. The following figure shows the failures and the analysis in a Weibull++ standard folio.
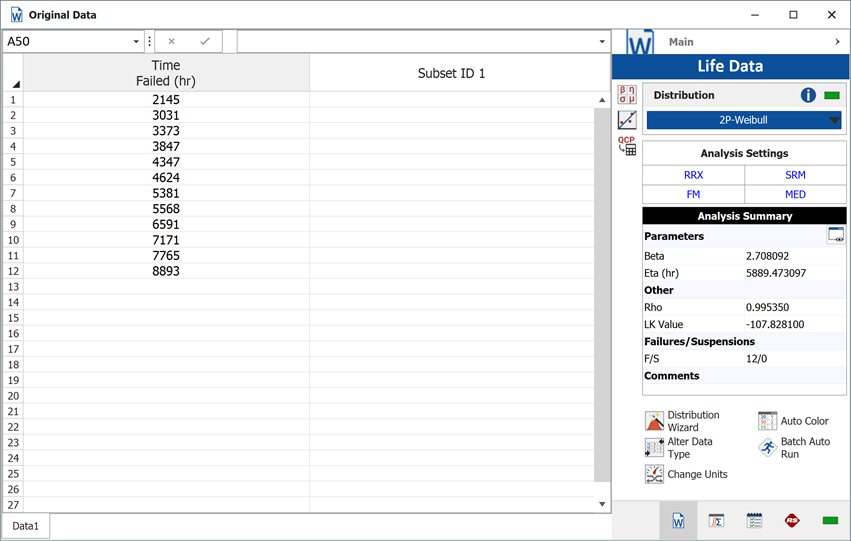
The analysts believe that the planned design improvements will yield 50% effectiveness. To estimate the reliability of the product based on the assumptions about the repair effectiveness, they enter the data in groups, counting a 0.5 failure for each group. The following figure shows the adjusted data set and the calculated parameters.
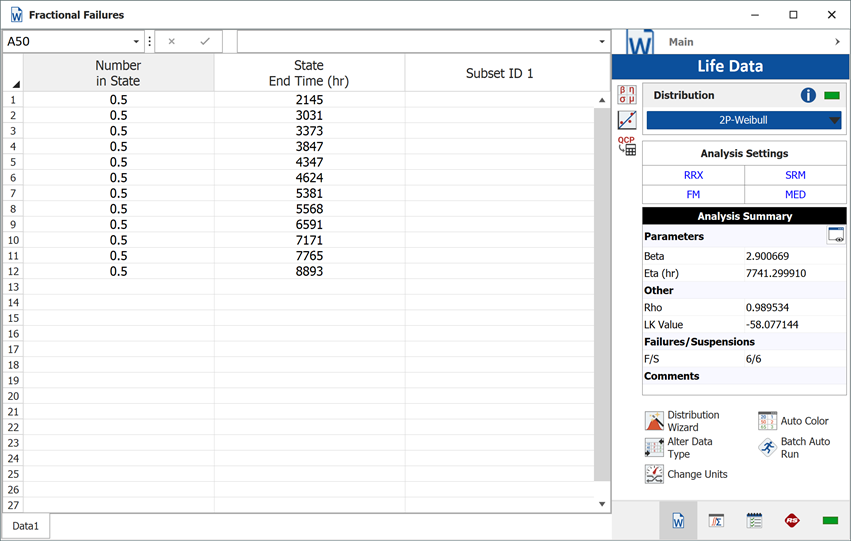
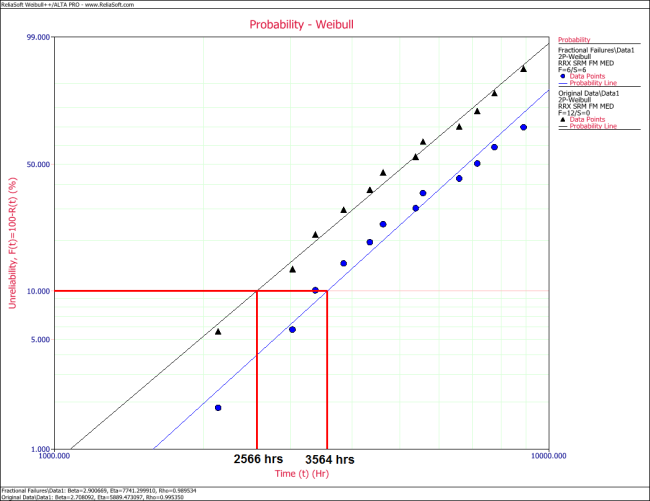
The following overlay plot of unreliability vs. time shows that by using fractional failures the estimated unreliability of the component has decreased, while the B10 life has increased from 2,566 hours to 3,564 hours.
Plots
In addition to the probability plots required in life data analysis, accelerated life test data analysis utilizes a variety of stress-related plots. Each plot provides information crucial to performing accelerated life test analyses. The addition of stress dependency into the life equations introduces another dimension into the plots. This generates a whole new family of 3-dimensional (3D) plots. The following table summarizes the types of plots available for ALTA folios in ReliaSoft's Weibull++.
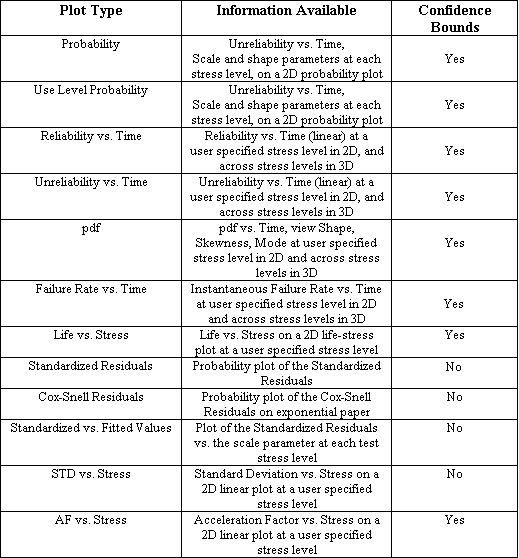
Considerations relevant to the use of some of the plots available in Weibull++ are discussed in the sections that follow.
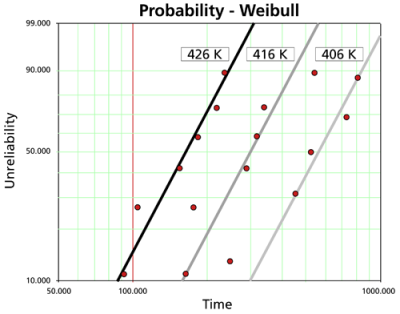
Probability Plots
The probability plots used in accelerated life testing data analysis are similar to those used in life data analysis. The only difference is that each probability plot in accelerated testing is associated with the corresponding stress or stresses. Multiple lines will be plotted on a probability plot in Weibull++, each corresponding to a different stress level. The information that can be obtained from probability plots includes: reliability with confidence bounds, warranty time with confidence bounds, shape and scale parameters, etc.
Reliability and Unreliability Plots
There are two types of reliability plots. The first type is a 2-dimensional plot of Reliability vs. Time for a given stress level. The second type is a 3-dimensional plot of the Reliability vs. Time vs. Stress. The 2-dimensional plot of reliability is just a section of the 3-dimensional plot at the desired stress level, as illustrated in the next figure.
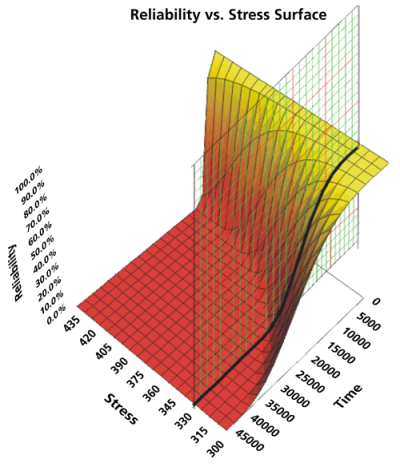
A Reliability vs. Time plot provides reliability values at a given time and time at a given reliability. These can be plotted with or without confidence bounds. The same 2-dimensional and 3-dimensional plots are available for unreliability as well, and they are just the complement of the reliability plots.
Failure Rate Plots
The instantaneous failure rate is a function of time and stress. For this reason, a 2-dimensional plot of Failure Rate vs. Time at a given stress and a 3-dimensional plot of Failure Rate vs. Time and Stress can be obtained in Weibull++.
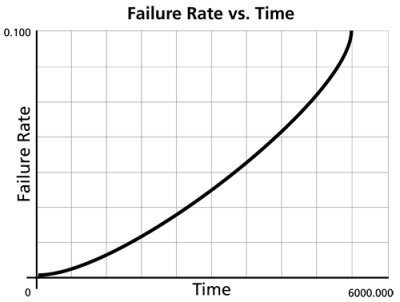
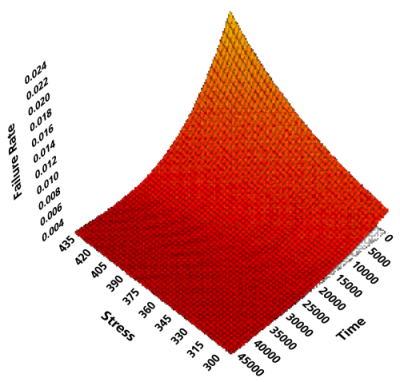
A failure rate plot shows the expected number of failures per unit time at a particular stress level (e.g., failures per hour at 410K).
Pdf Plots
The pdf is a function of time and stress. For this reason, a 2-dimensional plot of the pdf vs. Time at a given stress and a 3-dimensional plot of the pdf vs. Time and Stress can be obtained in Weibull++.
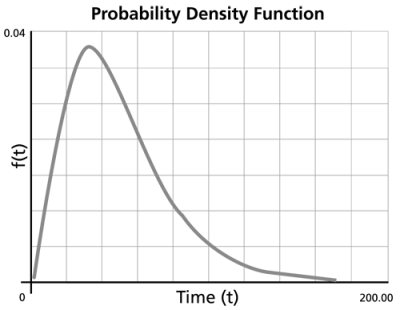
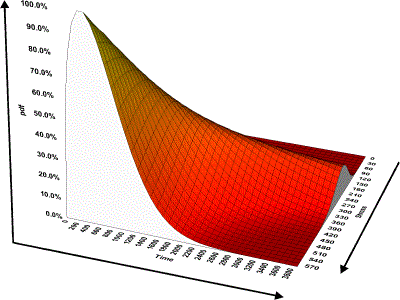
A pdf plot represents the relative frequency of failures as a function of time and stress. Although the pdf plot is less important in most reliability applications than the other plots available in Weibull++, it provides a good way of visualizing the distribution and its characteristics such as its shape, skewness, mode, etc.
Life-Stress Plots
Life vs. Stress plots and Probability plots are the most important plot types in accelerated life testing analysis. Life vs. Stress plots are widely used for estimating the parameters of life-stress relationships. Any life measure can be plotted versus stress in the Life vs. Stress plots available in Weibull++. Confidence bounds information on each life measure can also be plotted. The most widely used Life vs. Stress plots are the Arrhenius and the inverse power law plots. The following figure illustrates a typical Arrhenius Life vs. Stress plot.
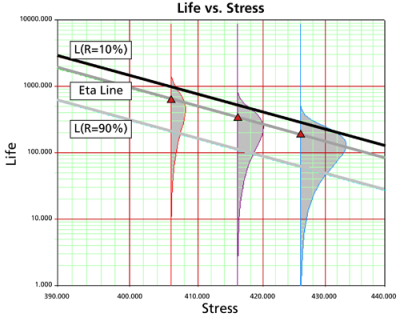
Each line in the figure above represents the path for extrapolating a life measure, such as a percentile, from one stress level to another. The slope and intercept of those lines are the parameters of the life-stress relationship (whenever the relationship can be linearized). The imposed pdfs represent the distribution of the data at each stress level.
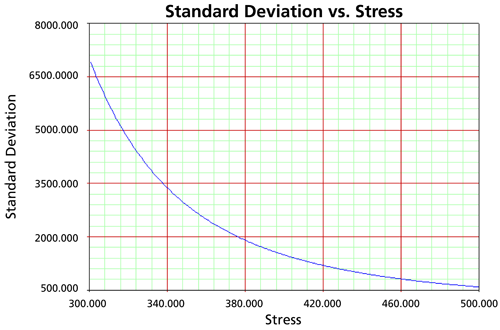
Standard Deviation Plots
Standard Deviation vs. Stress is a useful plot in accelerated life testing analysis and provides information about the spread of the data at each stress level.
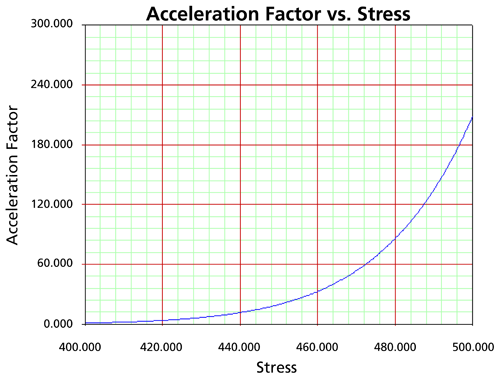
Acceleration Factor Plots
The acceleration factor is a unitless number that relates a product's life at an accelerated stress level to the life at the use stress level. It is defined by:


where:
-
-
 is the life at the use stress level.
is the life at the use stress level. is the life at the accelerated level.
is the life at the accelerated level.
-


As it can be seen, the acceleration factor depends on the life-stress relationship (i.e., Arrhenius, Eyring, etc.) and is thus a function of stress.
The Acceleration Factor vs. Stress plot is generated using the equation above at a constant use stress level and at a varying accelerated stress. In the below figure, the Acceleration Factor vs. Stress was plotted for a constant use level of 300K. Since
 , the value of the acceleration factor at 300K is equal to 1. The acceleration factor for a temperature of 450K is approximately 8. This means that the life at the use level of 300K is eight times higher than the life at 450K.
, the value of the acceleration factor at 300K is equal to 1. The acceleration factor for a temperature of 450K is approximately 8. This means that the life at the use level of 300K is eight times higher than the life at 450K.

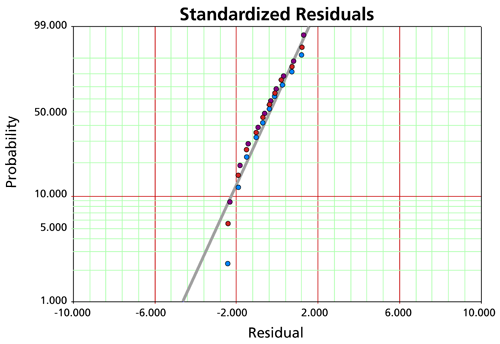
Residual Plots
Residual analysis for reliability consists of analyzing the results of a regression analysis by assigning residual values to each data point in the data set. Plotting these residuals provides a very good tool in assessing model assumptions and revealing inadequacies in the model, as well as revealing extreme observations. Three types of residual plots are available in Weibull++.
Standardized Residuals (SR)
The standardized residuals plot for the Weibull and lognormal distributions can be obtained in Weibull++. Each plot type is discussed next.
SR for the Weibull Distribution
Once the parameters have been estimated, the standardized residuals for the Weibull distribution can be calculated by:

![{\displaystyle {{\widehat {e}}_{i}}={\widehat {\beta }}\left[\ln({{T}_{i}})-\ln({\widehat {\eta }}(V))\right]\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/e0d5a08e92d0d5626b25a0a798065f36652d7213)
Then, under the assumed model, these residuals should look like a sample from an extreme value distribution with a mean of 0. For the Weibull distribution the standardized residuals are plotted on a smallest extreme value probability paper. If the Weibull distribution adequately describes the data, then the standardized residuals should appear to follow a straight line on such a probability plot. Note that when an observation is censored (suspended), the corresponding residual is also censored.
SR for the Lognormal Distribution
Once the parameters have been estimated, the fitted or calculated responses can be calculated by:


Then, under the assumed model, the standardized residuals should be normally distributed with a mean of 0 and a standard deviation of 1 (
 ). Consequently, the standardized residuals for the lognormal distribution are commonly displayed on a normal probability plot.
). Consequently, the standardized residuals for the lognormal distribution are commonly displayed on a normal probability plot.

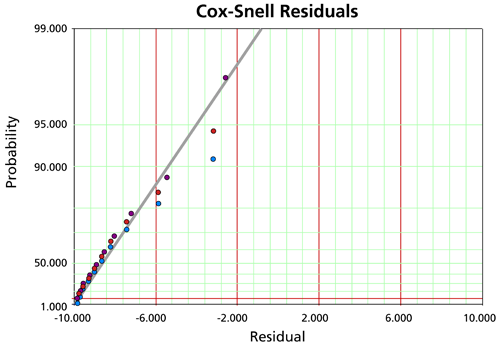
Cox-Snell Residuals
The Cox-Snell residuals are given by:

![{\displaystyle {{\widehat {e}}_{i}}=-\ln[R({{T}_{i}})]\,\!}](https://en.wikipedia.org/api/rest_v1/media/math/render/svg/6afc133958f59a74b3e2df56e8f9a160062606f8)
where  is the calculated reliability value at failure time
is the calculated reliability value at failure time
 The Cox-Snell residuals are plotted on an exponential probability paper.
The Cox-Snell residuals are plotted on an exponential probability paper.


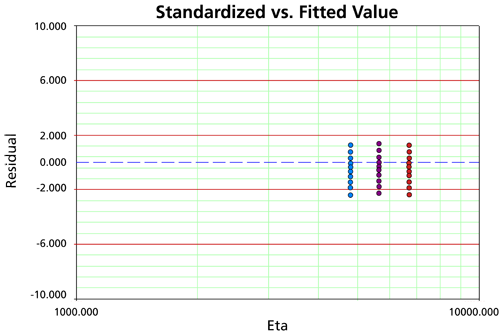
Standardized vs. Fitted Values
A Standardized vs. Fitted Value plot helps to detect behavior not modeled in the underlying relationship. However, when heavy censoring is present, the plot is more difficult to interpret. In a Standardized vs. Fitted Value plot, the standardized residuals are plotted versus the scale parameter of the underlying life distribution (which is a function of stress) on log-linear paper (linear on the Y-axis). Therefore, the standardized residuals are plotted versus
 for the Weibull distribution, versus
for the Weibull distribution, versus
 for the lognormal distribution and versus
for the lognormal distribution and versus
 for the exponential distribution.
for the exponential distribution.