Batch Auto Run
The Batch Auto Run utility allows you to extract data subsets from an existing data set in a life data folio or a reliability growth data folio. The options depend on the folio type.
Life Data Folios
For life data folios, consider a data sheet that contains the failure times for a product manufactured in two different plants. By using Batch Auto Run, you can filter the data by manufacturing plant and then analyze the failures from each plant separately.
Batch Auto Run Setup
To use the tool, you must first define a subset ID for each data point you want to extract, making sure that the data points you wish to group together all have the same subset ID.
Note: The subset ID can be any text up to 30 characters, including spaces. For example, "A _ _ X" is not the same as "A _ X" where " _ " is used to designate a space.
Open the utility by choosing Life Data > Options > Batch Auto Run or by clicking the icon on the Main page of the control panel.
![]()
You will be presented with a list of all the subset IDs in your data sheet, as shown in the following example.
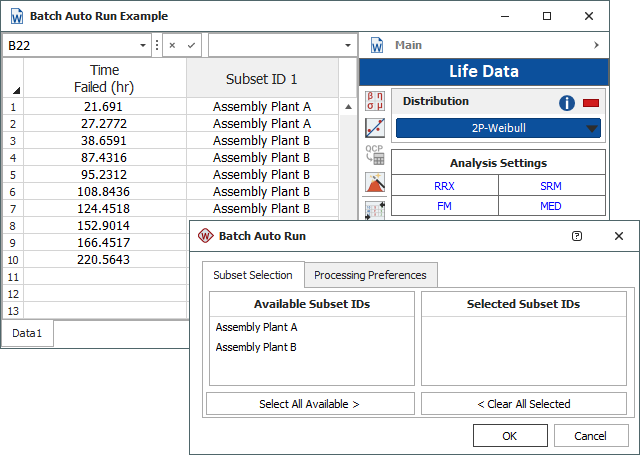
Double-click an available subset ID to include it in the batch auto run process or drag the subset ID to the Selected Subset IDs column. If you have more than one subset ID column in your data sheet, a drop-down list will be available to allow you to choose which column to use in the analysis.
You can also click the Select All Available button to automatically include all subset IDs in the column in the batch auto run process. Each selected subset ID will be extracted to its own separate data sheet at the end of the batch auto run process.
Processing Preferences
You can set your preferences for how the data will be processed on the Processing Preferences tab. When you change the settings and click OK, your preferences will be saved as the default settings for the next time you apply the batch auto run process for any Weibull++ life data folio.
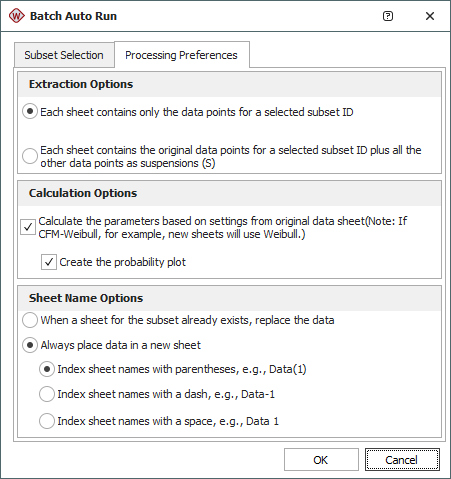
Extraction Options set how the data of the selected subset IDs will be extracted. The first option simply extracts the data points for each subset ID into separate data sheets so that you can analyze the data separately.
The second option extracts the data sets that are required to perform a competing failure modes (CFM) analysis. For example, consider a device that has three competing failure modes A, B and C. When you extract the data points of mode A, the Batch Auto Run utility will retain all the data points due to mode A but mark all other data points due to modes B and C as suspensions. In CFM analysis, the data points of modes B and C are considered to be suspensions because if they did not exist, all the units will have failed at some point in the future due to mode A. For an example on how to use this setting, see Competing Failure Modes (CFM) Analysis.
Calculation Options allow you select whether to automatically analyze the extracted data sheets and create a probability plot. The parameters of the extracted data sheet will be calculated using the same analysis settings specified for the original data sheet.
Sheet Names Options specifies where to put the extracted data. The first time you run the batch auto run process, the utility will extract the data points into new data sheets with the same names as the subset IDs. If you run the process again for the same subset IDs, you will have the option to either replace the data in the existing sheets or to always extract the data to new sheets.
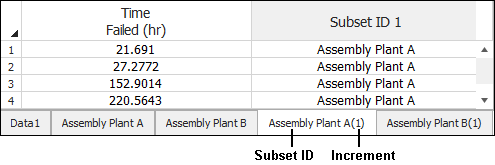
If you select the Always place data in a new sheet option, the data will be extracted to another new data sheet with the same name as the subset ID plus an increment to reflect the number of additional data sheets that have been created for the same subset ID. The increments can be separated by parentheses, a dash or a space. The following example shows the increment number separated by parentheses.
Reliability Growth Data (RGA) Folios
For fielded data or with some of the multiple systems data types (Concurrent Operating Times, with Dates and with Event Codes), you can use Batch Auto Run to extract all the data that relates to a particular system ID.
For multi-phase data, you can use Batch Auto Run to extract all the events (i.e., failures, time of implemented fixes, etc.) that occurred within a particular phase or analysis point.
To use Batch Auto Run, choose Growth Data > Options > Batch Auto Run or click the icon on the Main page of the control panel.
![]()
You will be presented with a list of all the available subsets in your data sheet, similar to the examples shown next.
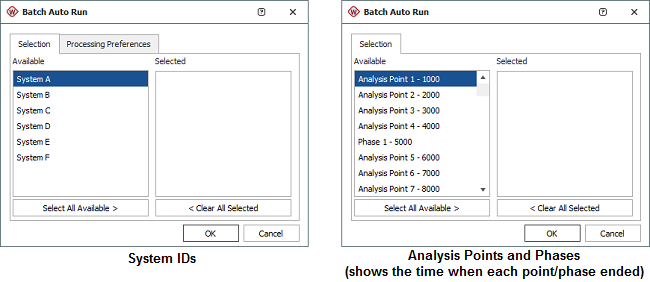
Double-click an available subset to include it in the batch auto run process or drag the subset to the Selected column. You can also click the Select All Available button to automatically include all subsets in the process.
If you are extracting data based on the system ID, you can choose to extract the selected subsets into individual data sheets by clicking the Processing Preferences tab and selecting the Place each system in an individual sheet check box. Otherwise, clear the option if you prefer to have the selected subsets appear all together in one data sheet.
Tip: If you wish to extract the first times-to-failure of all unique BC modes or unique BD modes in a data set, use the Mode Processing window.