Discussion
of the Residual Sum of Squares in DOE
[Editor's Note: This article has been updated since its original publication to reflect a more recent version of the software interface.]
Variation occurs in nature, be it the tensile strength of a particular grade of steel, the caffeine content in your energy drink or the distance traveled by your vehicle in a day. Variations are also seen in the observations recorded during multiple executions of a process, even when conditions are kept as homogeneous as possible. The natural variations that occur in a process, even when all factors are maintained at the same level, are often termed noise. In Design of Experiments (DOE) analysis, a key goal is to study the effect(s) of one or more factors on measurements of interest (or responses) for a product or process. It thus becomes extremely important to distinguish the changes in the response caused by a factor from those caused by noise. A number of statistical methods, generally referred to as hypothesis testing, are available to achieve this. These methods normally involve quantifying the variability due to noise or error in conjunction with the variability due to different factors and their interactions. It is then possible to determine whether the changes observed in the response(s) due to changes in the factor(s) are significant.
In this article, we will discuss different components of error and give an example of how the error and each of its components are defined and used in the context of hypothesis testing.
Background
In a DOE analysis, the error is quantified in terms of the residual sum of squares. To illustrate this, consider the standard regression model:
|
|
where a and b are coefficients and εi is the error term.
Given this model, the fitted value of yi is:
|
|
(2) |
where
![]() and
and
![]() are
estimated coefficients.
are
estimated coefficients.
The discrepancy between the observed value and the fitted value is called the residual. Note that while the residual and the error term are often used interchangeably, the residual is the estimate of the error term εi.
The residual sum of squares (SSE) is an overall measurement of the discrepancy between the data and the estimation model. The smaller the discrepancy, the better the model's estimations will be. The discrepancy is quantified in terms of the sum of squares of the residuals.
|
|
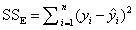
The sum of squares of the residuals usually can be divided into two parts: pure error and lack of fit. They are discussed in subsequent sections.
As mentioned, it is of great importance to be able to identify which terms are significant. (The word term refers to an effect in the model for example, the effect of factor A, the effect of factor B or the effect of their interaction, AB.) To accomplish this, the mean square of the term of interest is tested against the error mean square. The mean square of the error is defined as the sum of squares of the error divided by the degrees of freedom attributed to the error.
|
|
(4) |
The degrees of freedom of the error is the number of observations in excess of the unknowns. For example, if there are 3 unknowns and 7 independent observations are taken then the degrees of freedom value is 4 (7 − 3 = 4).
The mean square of a term is defined as the sum of squares of that term divided by the degrees of freedom attributed to that term.
|
|
(5) |
The degrees of freedom of a term is the number of independent effects for that term. For example, for a factor with 4 levels (i.e. 4 different factor values or settings), only three are independent. The degrees of freedom value associated with that term is then 3. For more information, see [1].
To test the hypothesis H0: the tested term is not significant, a test statistic is needed. The ratio between the term mean square and the error mean square is called the F ratio.
|
|
(6) |
It can be shown that if a term is not significant, this ratio follows the F distribution. H0 is rejected (i.e. the term is considered significant) if:
![]()
where
![]() is the percentile of the F distribution corresponding to
a cumulative probability of (1-
α) and
α is the significance
level.
is the percentile of the F distribution corresponding to
a cumulative probability of (1-
α) and
α is the significance
level.
Example
The following example shows the definition and applications of the residual sum of squares, the pure error and the lack of fit.
Consider the following two-level design, where the two levels are coded as -1 and 1. Y is the measurement of interest or the response. The obtained measurements are shown next.
| A | B | Y |
| -1 | -1 | 12 |
| 1 | -1 | 1 |
| -1 | 1 | 32 |
| 1 | 1 | 9 |
| -1 | -1 | 23 |
| 1 | -1 | 3 |
| -1 | 1 | 10 |
| 1 | 1 | 8 |
Each run of this experiment involves a combination of the levels of the investigated factors, A and B. Each of these combinations is referred to as a treatment. Since there are two factors with two levels each, there are 4 (22 = 4) possible combinations for the factor settings. Since all possible combinations are present, this design is called a full factorial design.
Multiple runs at a given treatment are called replicates. This particular example has 2 replicates for each treatment (i.e. there are 2 replicates of the treatment with A = -1 and B = -1, 2 replicates of the treatment with A = 1 and B = -1, etc.)
Analysis Results
Assuming that the interaction term is not of interest, the following results are obtained from ReliaSoft's DOE++ software.

Figure 1: DOE++ Analysis Results
The following discussion will focus on the section marked above in red.
Residual Error
The regression model in this analysis, not considering the interaction term AB, is:
|
|
(7) |
with α0 = 12.25, α1 = -7 and α2 = 2.5 (obtained from the Regression Information Table above under the Coefficient column). The residual sum of squares can then be obtained using equation (1).
![]()
Given 3 unknowns in the model, α0, α1 and α2, and 8 observations, the degrees of freedom of the error can be found.
Pure Error
Pure error reflects the variability of the observations within each treatment. The sum of squares for the pure error is the sum of the squared deviations of the responses from the mean response in each set of replicates.
In this example, there are four treatments. The mean values for the treatments are shown below.
| A | B | Y mean |
| -1 | -1 | 17.5 |
| 1 | -1 | 2 |
| -1 | 1 | 21 |
| 1 | 1 | 8.5 |
The pure error can be calculated as follows.
- The pure error for the treatment with A = -1 and B = -1 is:
![]()
- The pure error for the treatment with A = 1 and B = -1 is:
![]()
- The pure error for the treatment with A = -1 and B = 1 is:
![]()
- The pure error for the treatment with A = 1 and B = 1 is:
![]()
- The pure error sum of squares is then:
![]()
The degrees of freedom corresponding to the pure error sum of squares is:
![]()
where n is the number of treatments and m is the number of replicates.
For the above example:
![]()
The mean square of the pure error can now be obtained as follows:
![]()
The mean square of the pure error can then be used to test the adequacy of the model as shown in the next section.
Lack of Fit Error
The lack of fit measures the error due to deficiency in the model. In this particular example, the deficiency is explained by the missing term AB in the model.
If a regression model fits the data well, the mean square of the lack of fit error should be close to the mean square of the pure error. Therefore, the lack of fit error can be used to test whether the model can fit the data well. If the lack of fit term is significant, on the other hand, we would reject the null hypothesis and would conclude that the model is not adequate.
The lack of fit sum of squares is calculated as follows:
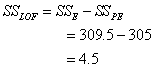
The degrees of freedom are calculated as follows:
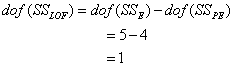
The mean square of the lack of fit can be obtained by:
![]()
The statistic to test the significance of the lack of fit can then be calculated as follows:
![]()
Note that when we are testing for significance of the lack of fit, the denominator is the mean square of the pure error, while when we are testing for significance of a term in the model, the denominator is the mean square of the residual as shown in equation (3).
The critical value for this test at a 0.05 significance level is:
![]()
Since
![]() (0.59 < 7.709), at a significance level of 0.05, we fail
to reject the hypothesis that the model adequately fits
the data. In other words, at that significance level, it
is acceptable to use the reduced model that does not include
the interaction term.
(0.59 < 7.709), at a significance level of 0.05, we fail
to reject the hypothesis that the model adequately fits
the data. In other words, at that significance level, it
is acceptable to use the reduced model that does not include
the interaction term.
Alternatively, we could also find the lowest significance level, α, that would lead to the rejection of the null hypothesis at the given value of the test statistic and to the conclusion that the model is not acceptable. This is also called the p value and it is defined as:
![]()
For this example, it can be calculated as follows:
![]()
Conclusion
This article presented some background on the calculation of the error and its different components. Of particular interest was the use of the mean square of the pure error and the lack of fit to test for the validity of the chosen model. Although not illustrated here, once the residual error is obtained, it can be used to test for the significance of any term in the model.
References
[1] ReliaSoft Corporation, Experiment Design and Analysis Reference, ReliaSoft Publishing, Tucson, AZ, 2008.